
- Read more about USER-IN-THE-LOOP VIEW SAMPLING WITH ERROR PEAKING VISUALIZATION
- Log in to post comments
Augmented reality (AR) provides ways to visualize missing view samples for novel view synthesis. Existing approaches present 3D annotations for new view samples and task users with taking images by aligning the AR display. This data collection task is known to be mentally demanding and limits capture areas to pre-defined small areas due to ideal but restrictive underlying sampling theory. To free users from 3D annotations and limited scene exploration, we propose using locally reconstructed light fields and visualizing errors to be removed by inserting new views.
- Categories:
 127 Views
127 Views
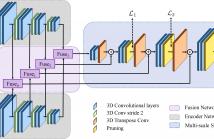
- Read more about Dynamic Point Cloud Interpolation
- Log in to post comments
Dense photorealistic point clouds can depict real-world dynamic objects in high resolution and with a high frame rate. Frame interpolation of such dynamic point clouds would enable the distribution, processing, and compression of such content. In this work, we propose a first point cloud interpolation framework for photorealistic dynamic point clouds. Given two consecutive dynamic point cloud frames, our framework aims to generate intermediate frame(s) between them.
- Categories:
50 Views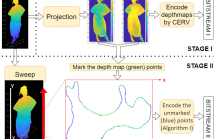
- Read more about Refining the bounding volumes for lossless compression of voxelized point clouds geometry
- Log in to post comments
- Categories:
37 Views
- Read more about Translation of a Higher Order Ambisonics Sound Scene Based on Parametric Decomposition
- Log in to post comments
This paper presents a novel 3DoF+ system that allows to navigate, i.e., change position, in scene-based spatial audio content beyond the sweet spot of a Higher Order Ambisonics recording. It is one of the first such systems based on sound capturing at a single spatial position. The system uses a parametric decomposition of the recorded sound field. For the synthesis, only coarse distance information about the sources is needed as side information but not the exact number of them.
handout.pdf
- Categories:
87 Views
- Read more about Interactive Low Latency Video Streaming Of Volumetric Content
- Log in to post comments
Low latency video streaming of volumetric content is an emerging technology to enable immersive media experiences on mobile devices. Unlike 3DoF scenarios where users are restricted to changes of their head orientation at a single position, volumetric content allows users to move freely within the scene in 6DoF. Although the processing power of mobile devices has increased considerably, streaming volumetric content directly to such devices is still challenging. High-quality volumetric content requires significant data rate and network bandwidth.
- Categories:
287 Views
- Read more about TOWARDS MODELLING OF VISUAL SALIENCY IN POINT CLOUDS FOR IMMERSIVE APPLICATIONS
- Log in to post comments
Modelling human visual attention is of great importance in the field of computer vision and has been widely explored for 3D imaging. Yet, in the absence of ground truth data, it is unclear whether such predictions are in alignment with the actual human viewing behavior in virtual reality environments. In this study, we work towards solving this problem by conducting an eye-tracking experiment in an immersive 3D scene that offers 6 degrees of freedom. A wide range of static point cloud models is inspected by human subjects, while their gaze is captured in real-time.
- Categories:
38 Views
- Read more about BODYFITR: Robust automatic 3D human body fitting
- Log in to post comments
This paper proposes BODYFITR, a fully automatic method to fit a human body model to static 3D scans with complex poses. Automatic and reliable 3D human body fitting is necessary for many applications related to healthcare, digital ergonomics, avatar creation and security, especially in industrial contexts for large-scale product design. Existing works either make prior assumptions on the pose, require manual annotation of the data or have difficulty handling complex poses.
- Categories:
135 Views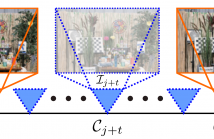
- Read more about FAST: Flow-Assisted Shearlet Transform for Densely-sampled Light Field Reconstruction
- Log in to post comments
Shearlet Transform (ST) is one of the most effective methods for Densely-Sampled Light Field (DSLF) reconstruction from a Sparsely-Sampled Light Field (SSLF). However, ST requires a precise disparity estimation of the SSLF. To this end, in this paper a state-of-the-art optical flow method, i.e. PWC-Net, is employed to estimate bidirectional disparity maps between neighboring views in the SSLF. Moreover, to take full advantage of optical flow and ST for DSLF reconstruction, a novel learning-based method, referred to as Flow-Assisted Shearlet Transform (FAST), is proposed in this paper.
- Categories:
58 Views
- Read more about PPSAN: PERCEPTUAL-AWARE 3D POINT CLOUD SEGMENTATION VIA ADVERSARIAL LEARNING
- Log in to post comments
Point cloud segmentation is a key problem of 3D multimedia signal processing. Existing methods usually use single network structure which is trained by per-point loss. These methods mainly focus on geometric similarity between the prediction results and the ground truth, ignoring visual perception difference. In this paper, we present a segmentation adversarial network to overcome the drawbacks above. Discriminator is introduced to provide a perceptual loss to increase the rationality judgment of prediction and guide the further optimization of the segmentator.
- Categories:
35 Views