
- Read more about Efficient Parameter Estimation for Semi-Continuous Data: An Application to Independent Component Analysis
- Log in to post comments
MLSP_2019.pdf
- Categories:
 12 Views
12 Views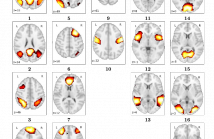
- Read more about HOW MANY FMRI SCANS ARE NECESSARY AND SUFFICIENT FOR RESTING BRAIN CONNECTIVITY ANALYSIS?
- Log in to post comments
Functional connectivity analysis by detecting neuronal coactivation in the brain can be efficiently done using Resting State Functional Magnetic Resonance Imaging (rs-fMRI) analysis. Most of the existing research in this area employ correlation-based group averaging strategies of spatial smoothing and temporal normalization of fMRI scans, whose reliability of results heavily depends on the voxel resolution of fMRI scan as well as scanning duration. Scanning period from 5 to 11 minutes has been chosen by most of the studies while estimating the connectivity of brain networks.
- Categories:
29 Views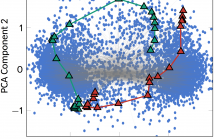
- Read more about Deep attractor networks for speaker re-identification and blind source separation
- Log in to post comments
Deep Clustering (DC) and Deep Attractor Networks (DANs) are a data-driven way to monaural blind source separation.
Both approaches provide astonishing single channel performance but have not yet been generalized to block-online processing.
When separating speech in a continuous stream with a block-online algorithm, it needs to be determined in each block which of the output streams belongs to whom.
In this contribution we solve this block permutation problem by introducing an additional speaker identification embedding to the DAN model structure.
- Categories:
28 Views
- Read more about TasNet: time-domain audio separation network for real-time, single-channel speech separation
- Log in to post comments
Robust speech processing in multi-talker environments requires effective speech separation. Recent deep learning systems have made significant progress toward solving this problem, yet it remains challenging particularly in real-time, short latency applications. Most methods attempt to construct a mask for each source in time-frequency representation of the mixture signal which is not necessarily an optimal representation for speech separation.
- Categories:
86 Views
- Read more about Semi-Supervised Adversarial Audio Source Separation applied to Singing Voice Extraction
- Log in to post comments
The state of the art in music source separation employs neural networks trained in a supervised fashion on multi-track databases to estimate the sources from a given mixture. With only few datasets available, often extensive data augmentation is used to combat overfitting. Mixing random tracks, however, can even reduce separation performance as instruments in real music are strongly correlated. The key concept in our approach is that source estimates of an optimal separator should be indistinguishable from real source signals.
- Categories:
23 Views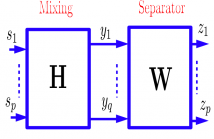
In this article, we propose a Bounded Component Analysis (BCA) approach for the separation of the convolutive mixtures of sparse sources. The corresponding algorithm is derived from a geometric objective function defined over a completely deterministic setting. Therefore, it is applicable to sources which can be independent or dependent in both space and time dimensions. We show that all global optima of the proposed objective are perfect separators. We also provide numerical examples to illustrate the performance of the algorithm.
- Categories:
33 Views
- Read more about Learning complex-valued latent filters with absolute cosine similarity
- Log in to post comments
- Categories:
12 Views- Read more about Learning complex-valued latent filters with absolute cosine similarity
- Log in to post comments
We propose a new sparse coding technique based on the power mean of phase-invariant cosine distances. Our approach is a generalization of sparse filtering and K-hyperlines clustering. It offers a better sparsity enforcer than the L1/L2 norm ratio that is typically used in sparse filtering. At the same time, the proposed approach scales better than the clustering counter parts for high-dimensional input. Our algorithm fully exploits the prior information obtained by preprocessing the observed data with whitening via an efficient row-wise decoupling scheme.
- Categories:
11 Views
- Read more about LOW-LATENCY SOUND SOURCE SEPARATION USING DEEP NEURAL NETWORKS
- Log in to post comments
Sound source separation at low-latency requires that each in- coming frame of audio data be processed at very low de- lay, and outputted as soon as possible. For practical pur- poses involving human listeners, a 20 ms algorithmic delay is the uppermost limit which is comfortable to the listener. In this paper, we propose a low-latency (algorithmic delay ≤ 20 ms) deep neural network (DNN) based source sepa- ration method.
- Categories:
32 Views