- Read more about EFFICIENT FUSION OF DEPTH INFORMATION FOR DEFOCUS DEBLURRING
- 1 comment
- Log in to post comments
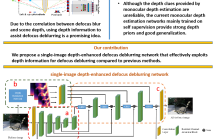
Defocus deblurring is a classic problem in image restoration tasks. The formation of its defocus blur is related to depth. Recently, the use of dual-pixel sensor designed according to depth-disparity characteristics has brought great improvements to the defocus deblurring task. However, the difficulty of real-time acquisition of dual-pixel images brings difficulties to algorithm deployment. This inspires us to remove defocus blur by single image with depth information.
- Categories:
 110 Views
110 Views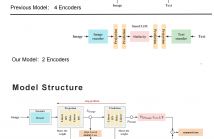
- Read more about SiamCLIM: Text-Based Pedestrian Search via Multi-modal Siamese Contrastive Learning
- Log in to post comments
Text-based pedestrian search (TBPS) aims at retrieving target persons from the image gallery through descriptive text queries. Despite remarkable progress in recent state-of-the-art approaches, previous works still struggle to efficiently extract discriminative features from multi-modal data. To address the problem of cross-modal fine-grained text-to-image, we proposed a novel Siamese Contrastive Language-Image Model (SiamCLIM).
SiamCLIM.pptx
- Categories:
27 Views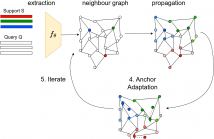
- Read more about Adaptive Anchor Label Propagation for Transductive Few-Shot Learning
- Log in to post comments
Few-shot learning addresses the issue of classifying images using limited labeled data. Exploiting unlabeled data through the use of transductive inference methods such as label propagation has been shown to improve the performance of few-shot learning significantly. Label propagation infers pseudo-labels for unlabeled data by utilizing a constructed graph that exploits the underlying manifold structure of the data.
- Categories:
32 Views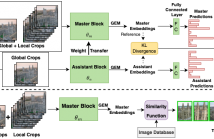
- Read more about MABNet: Master Assistant Buddy Network with Hybrid Learning for Image Retrieval
- Log in to post comments
Image retrieval has garnered a growing interest in recent times. The current approaches are either supervised or self-supervised. These methods do not exploit the benefits of hybrid learning using both supervision and self-supervision. We present a novel Master Assistant Buddy Network (MABNet) for image retrieval which incorporates both the learning mechanisms. MABNet consists of master and assistant block, both learning independently through supervision and collectively via self-supervision.
MABNET_ICASSP (6).pdf
- Categories:
15 Views
- Read more about Invert-and-project (IVP)-A Lossless Compression Method of Multi-scale JPEG Images via DCT Coefficients Prediction
- Log in to post comments
JPEG is a versatile and widely used format for images. Based an elegant design that enables the joint works of basis transformation (gross-scale decorrelation) and entropy coding (fine-scale coding), the resulting JPEG image can maintain virtually all visible features of an image while reducing its size to one tens of the original raw data.
- Categories:
44 Views
- Read more about Progressive-Granularity Retrieval via Hierarchical Feature Alignment for Person Re-Identification
- Log in to post comments
- Categories:
14 Views
- Read more about Medical image retrieval based on depth hash
- Log in to post comments
- Categories:
24 Views
- Read more about Fast Coding of Haar Wavelet Trees
- Log in to post comments
Tarter_DCC.pdf
- Categories:
84 Views
- Read more about Describe me if you can! Characterized instance-level human parsing
- Log in to post comments
Several computer vision applications such as person search or online fashion rely on human description. The use of instance-level human parsing (HP) is therefore relevant since it localizes semantic attributes and body parts within a person. But how to characterize these attributes? To our knowledge, only some single-HP datasets describe attributes with some color, size and/or pattern characteristics. There is a lack of dataset for multi-HP in the wild with such characteristics.
- Categories:
42 Views