- Read more about Investigating the Potential of Auxiliary-Classifier GANs for Image Classification in Low Data Regimes
- Log in to post comments
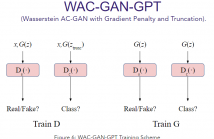
Generative Adversarial Networks (GANs) have shown promise in augmenting datasets and boosting convolutional neural networks' (CNN) performance on image classification tasks. But they introduce more hyperparameters to tune as well as the need for additional time and computational power to train supplementary to the CNN. In this work, we examine the potential for Auxiliary-Classifier GANs (AC-GANs) as a 'one-stop-shop' architecture for image classification, particularly in low data regimes.
- Categories:
 52 Views
52 Views
- Read more about Optimizing The Consumption Of Spiking Neural Networks With Activity Regularization
- Log in to post comments
- Categories:
15 Views
- Read more about Optimizing The Consumption Of Spiking Neural Networks With Activity Regularization
- Log in to post comments
- Categories:
18 Views
- Read more about PRIOR-BERT AND MULTI-TASK LEARNING FOR TARGET-ASPECT-SENTIMENT JOINT DETECTION
- Log in to post comments
Aspect-Based Sentiment Analysis (ABSA) is a fine-grained sentiment analysis task and has become a significant task with real-world scenario value. The challenge of this task is how to generate an effective text representation and construct an end-to-end model that can simultaneously detect (target, aspect, sentiment) triples from a sentence. Besides, the existing models do not take the heavily unbalanced distribution of labels into account and also do not give enough consideration to long-distance dependence of targets and aspect-sentiment pairs.
poster-new.pdf
- Categories:
32 Views
- Read more about PRIOR-BERT AND MULTITASK LEARNING FOR TARGET-ASPECT-SENTIMENT JOINT DETECTION
- Log in to post comments
Aspect-Based Sentiment Analysis (ABSA) is a fine-grained sentiment analysis task and has become a significant task with real-world scenario value. The challenge of this task is how to generate an effective text representation and construct an end-to-end model that can simultaneously detect (target, aspect, sentiment) triples from a sentence. Besides, the existing models do not take the heavily unbalanced distribution of labels into account and also do not give enough consideration to long-distance dependence of targets and aspect-sentiment pairs.
poster-new.pdf
- Categories:
27 Views
- Read more about SPE-44.3: A MODEL FOR ASSESSOR BIAS IN AUTOMATIC PRONUNCIATION ASSESSMENT (POSTER)
- Log in to post comments
- Categories:
21 Views
- Read more about SPE-44.3: A MODEL FOR ASSESSOR BIAS IN AUTOMATIC PRONUNCIATION ASSESSMENT (SLIDES)
- Log in to post comments
- Categories:
19 Views
- Read more about TED TALK TEASER GENERATION WITH PRE-TRAINED MODELS
- Log in to post comments
While we have seen significant advances in automatic summarization for text, research on speech summarization is still limited. In this work, we address the challenge of automatically generating teasers for TED talks. In the first step, we create a corpus for automatic summarization of TED and TEDx talks consisting of the talks' recording, their transcripts and their descriptions. The corpus is used to build a speech summarization system for the task. We adapt and combine pre-trained models for automatic speech recognition (ASR) and text summarization using the collected data.
- Categories:
16 Views
- Read more about LEARNING MONOCULAR 3D HUMAN POSE ESTIMATION WITH SKELETAL INTERPOLATION
- Log in to post comments
poster.pdf
- Categories:
30 Views
- Read more about A Novel Sequential Monte Carlo Framework For Predicting Ambiguous Emotion State (poster)
- Log in to post comments
- Categories:
31 Views