
- Read more about THE DAWN OF QUANTUM NATURAL LANGUAGE PROCESSING
- Log in to post comments
In this paper, we discuss the initial attempts at boosting understanding of human language based on deep-learning models with quantum computing. We successfully train a quantum-enhanced Long Short-Term Memory network to perform the parts-of-speech tagging task via numerical simulations. Moreover, a quantum-enhanced Transformer is proposed to perform the sentiment analysis based on the existing dataset.
- Categories:
 7 Views
7 Views
- Read more about A MULTI-RESOLUTION LOW-RANK TENSOR DECOMPOSITION
- Log in to post comments
The (efficient and parsimonious) decomposition of higher-order tensors is a fundamental problem with numerous applications in a variety of fields. Several methods have been proposed in the literature to that end, with the Tucker and PARAFAC decompositions being the most prominent ones. Inspired by the latter, in this work we propose a multi-resolution low-rank tensor decomposition to describe (approximate) a tensor in a hierarchical fashion.
- Categories:
36 Views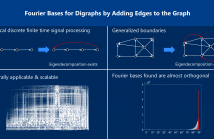
- Read more about Digraph Signal Processing with Generalized Boundary Conditions
- Log in to post comments
Signal processing on directed graphs (digraphs) is problematic, since the graph shift, and thus associated filters, are in general not diagonalizable. Furthermore, the Fourier transform in this case is now obtained from the Jordan decomposition, which may not be computable at all for large graphs. We propose a novel and general solution for this problem based on matrix perturbation theory: We design an algorithm that adds a small number of edges to a given digraph to destroy nontrivial Jordan blocks.
- Categories:
49 Views
- Read more about Robust Recovery of Jointly-Sparse Signals Using Minimax Concave Loss Function
- Log in to post comments
We propose a robust approach to recovering jointly sparse signals in the presence of outliers. The robust recovery task is cast as a convex optimization problem involving a minimax concave loss function (which is weakly convex) and a strongly convex regularizer (which ensures the overall convexity). The use of the nonconvex loss makes the problem difficult to solve directly by the convex optimization methods even with the well-established firm shrinkage.
- Categories:
13 Views
- Read more about A QUESTION-ORIENTED PROPAGATION NETWORK FOR NEWS READING COMPREHENSION
- Log in to post comments
- Categories:
15 Views

- Read more about ICASSP 2022 Presentation Ronchini
- Log in to post comments
This paper proposes a benchmark of submissions to Detection and Classification Acoustic Scene and Events 2021 Challenge (DCASE) Task 4 representing a sampling of the state-of-the-art in Sound Event Detection task. The submissions are evaluated according to the two polyphonic sound detection score scenarios proposed for the DCASE 2021 Challenge Task 4, which allow to make an analysis on whether submissions are designed to perform fine-grained temporal segmentation, coarse-grained temporal segmentation, or have been designed to be polyvalent on the scenarios proposed.
- Categories:
9 Views
- Read more about ICASSP_2022 Poster Ronchini
- Log in to post comments
This paper proposes a benchmark of submissions to Detection and Classification Acoustic Scene and Events 2021 Challenge (DCASE) Task 4 representing a sampling of the state-of-the-art in Sound Event Detection task. The submissions are evaluated according to the two polyphonic sound detection score scenarios proposed for the DCASE 2021 Challenge Task 4, which allow to make an analysis on whether submissions are designed to perform fine-grained temporal segmentation, coarse-grained temporal segmentation, or have been designed to be polyvalent on the scenarios proposed.
- Categories:
42 Views
- Read more about UNSUPERVISED ANOMALY DETECTION FOR CONTAINER CLOUD VIA BILSTM-BASED VARIATIONAL AUTO-ENCODER
- Log in to post comments
- Categories:
27 Views
Catastrophic forgetting is a thorny challenge when updating keyword spotting (KWS) models after deployment. To tackle such challenges, we propose a progressive continual learning strategy for small-footprint spoken keyword spotting (PCL-KWS). Specifically, the proposed PCL-KWS framework introduces a network instantiator to generate the task-specific sub-networks for remembering previously learned keywords. As a result, the PCL-KWS approach incrementally learns new keywords without forgetting prior knowledge.
- Categories:
23 Views