
- Read more about Burrows-Wheeler Transform on Purely Morphic Words
- 3 comments
- Log in to post comments
- Categories:
 82 Views
82 Views
- Read more about x3: Lossless Data Compressor
- Log in to post comments
x3 is a lossless optimizing dictionary-based data compressor. The algorithm uses a combination of a dictionary, context modeling, and arithmetic coding. Optimization adds the ability to find the most appropriate parameters for each file. Even without optimization, x3 can compress data with a compression ratio comparable to the best dictionary compression methods like LZMA, zstd, or Brotli.
slides.pdf
- Categories:
61 Views
- Read more about Contact Matrix Compressor
- 2 comments
- Log in to post comments
The study of three-dimensional folding of chromosomes is important to understand genomics processes. This is done through techniques, such as Hi-C, that analyze the spatial organization of chromosomes in a cell. The data coming from the study is a 2-dimensional quantitative maps with genomic coordinate systems. We present a novel approach called Contact Matrix Compressor(CMC) for the efficient compression of Hi-C data. By exploiting the properties of the data, such as diagonally dominant and symmetrical, CMC achieves a much higher compression.
- Categories:
44 Views
- Read more about On dynamic bitvector implementations
- 2 comments
- Log in to post comments
Bitvectors that support rank and select queries are the workhorses of succinct data structures, implementations of which are now widespread, for example, in bioinformatics software. To date, however, most bitvector implementations are static, thus forcing more complex data structures built from them to be static too. In this paper we explore dynamic bitvectors, which, in addition to rank and select queries, also support update operations, specifically: insert, remove, and modify. We first provide several practical optimizations to the recent B-tree based bitvectors of Prezza (Proc.
- Categories:
150 Views
- Read more about Selective Weighted Adaptive Coding
- 1 comment
- Log in to post comments
- Categories:
32 Views
- Read more about A Huffman Code Based Crypto-System
- 1 comment
- Log in to post comments
- Categories:
103 Views
- Read more about FM-Indexing Grammars Induced by Suffix Sorting for Long Patterns
- Log in to post comments
- Categories:
60 Views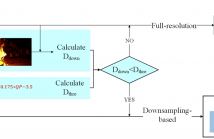
Resampling-based coding, i.e. down-sampling before encoding and up-sampling after decoding, has been recognized to be an effective tool for compressing high-resolution videos at low bitrates. The newest video coding standard, Versatile Video Coding (VVC), supports resampling-based coding via a mechanism named Reference Picture Resampling (RPR), where the spatial resolution can be changed without inserting an intra frame. Intuitively, it is not wise to utilize a single resolution throughout the whole video, because frames with different contents may prefer different coding resolutions.
- Categories:
271 Views
- Read more about Succinct Data Structure for Path Graphs
- Log in to post comments
We consider the problem of designing space-efficient data structures for unlabelled path graphs with n vertices while supporting basic navigational queries such as degree, adjacency, and neighborhood queries efficiently. We provide two solutions for this problem. Our first data structure is succinct and occupies n log n+o(n log n) bits while answering adjacency query in O(log n) time, and neighborhood and degree queries in O(d log^2 n) time where d is the degree of the queried vertex. Our second data structure answers all these queries faster at the expense of slightly more space.
- Categories:
40 Views