
- Read more about Information-Bottleneck-Based Behavior Representation Learning for Multi-agent Reinforcement Learning
- Log in to post comments
- Categories:
 17 Views
17 Views
- Read more about An Ensemble Learning Framework for Multi-class COVID-19 Lesion Segmentation from Chest CT Images
- Log in to post comments
The novel Coronavirus disease (COVID-19) has been the most critical global challenge over the past months. Lung involvement quantification and distinguishing the types of infections from chest CT scans can assist in accurate severity assessment of COVID-19 pneumonia, efficient use of limited medical resources, and saving more lives. Nevertheless, visual assessment of chest CT images and evaluating the disease severity by radiologists are expensive and prone to error.
- Categories:
75 Views
- Read more about Toward Semi autonomous Stiffness Adaptation of Pneumatic Soft Robots: Modeling and Validation
- Log in to post comments
- Categories:
19 Views
In human-machine systems (HMS), trust placed by humans on machines is a complex concept and attracts increasingly research efforts. Herein, we reviewed recent studies on building and measuring trust in HMS. The review was based on one comprehensive model of trust – IMPACTS, which has 7 features of intention, measurability, performance, adaptivity, communication, transparency, and security. The review found that, in the past 5 years, HMS fulfill the features of intention, measurability, communication, and transparency. Most of the HMS consider the feature of performance.
- Categories:
33 Views
- Read more about Estimation of Fields Using Binary Measurements From a Mobile Agent
- Log in to post comments
- Categories:
22 Views
- Read more about Improving a User's Haptic Perceptual Sensitivity by Optimizing Effective Manipulability of a Redundant User Interface
- Log in to post comments
Human perceptual sensitivity of various types of forces, e.g., stiffness and friction, is important for surgeons during robotic surgeries such as needle insertion and palpation. However, force feedback from robot end-effector is usually a combination of desired and undesired force components which could have an effect on the perceptual sensitivity of the desired one. In presence of undesired forces, to improve perceptual sensitivity of desired force could benefit robotic surgical outcomes.
- Categories:
15 Views
- Read more about Generating Human Readable Transcript for Automatic Speech Recognition with Pre-trained Language Model
- Log in to post comments
Modern Automatic Speech Recognition (ASR) systems can achieve high performance in terms of recognition accuracy. However, a perfectly accurate transcript still can be challenging to read due to disfluency, filter words, and other errata common in spoken communication. Many downstream tasks and human readers rely on the output of the ASR system; therefore, errors introduced by the speaker and ASR system alike will be propagated to the next task in the pipeline.
- Categories:
62 Views
- Read more about Assisted Learning: Cooperative AI with Autonomy
- Log in to post comments
- Categories:
13 Views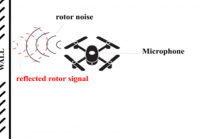
In this paper, we propose a method to estimate the proximity of an acoustic reflector, e.g., a wall, using ego-noise, i.e., the noise produced by the moving parts of a listening robot. This is achieved by estimating the times of arrival of acoustic echoes reflected from the surface. Simulated experiments show that the proposed non-intrusive approach is capable of accurately estimating the distance of a reflector up to 1 meter and outperforms a previously proposed intrusive approach under loud ego-noise conditions.
- Categories:
16 Views