
A learning algorithm referred to as Maximum Margin (MM) is proposed for considering the class-imbalance data learning issue: the deep model tends to predict the majority classes rather than the minority ones. For better generalization on the minority classes, the proposed Maximum Margin (MM) loss function is newly designed by minimizing a margin-based generalization bound through the shifting decision bound. As a prior study, the theoretically principled label-distributionaware margin (LDAM) loss had been successfully applied with classical strategies such as re-weighting or re-sampling.
- Categories:
 18 Views
18 Views
- Read more about Class Specific Interpretability in CNN Using Causal Analysis
- Log in to post comments
A singular problem that mars the wide applicability of machine learning (ML) models is the lack of generalizability and interpretability. The ML community is increasingly working on bridging this gap. Prominent among them are methods that study causal significance of features, with techniques such as Average Causal Effect (ACE). In this paper, our objective is to utilize the causal analysis framework to measure the significance level of the features in binary classification task.
- Categories:
30 Views
- Read more about MOBILE REGISTRATION NUMBER PLATE RECOGNITION USING ARTIFICIAL INTELLIGENCE
- Log in to post comments
Automatic License Plate Recognition (ALPR) for years has remained a persistent topic of research due to numerous practicable applications, especially in the Intelligent Transportation system (ITS). Many currently available solutions are still not robust in various real-world circumstances and often impose constraints like fixed backgrounds and constant distance and camera angles. This paper presents an efficient multi-language repudiate ALPR system based on machine learning.
- Categories:
40 Views
- Read more about Hyperspectral Segmentation for Paint Analysis
- Log in to post comments
- Categories:
7 Views
- Read more about Reinforced Curriculum Learning for Autonomous Driving in CARLA
- Log in to post comments
Autonomous Vehicles promise to transport people in a safer, accessible, and even efficient way. Nowadays, real-world autonomous vehicles are build by large teams from big companies with a tremendous amount of engineering effort. Deep Reinforcement Learning can be used instead, without domain experts, to learn end-to-end driving policies. Here, we combine Curriculum Learning with deep reinforcement learning, in order to learn without any prior domain knowledge, an end-to-end competitive driving policy for the CARLA autonomous driving simulator.
- Categories:
66 Views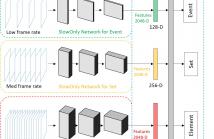
- Read more about Joint Learning On The Hierarchy Representation for Fine-Grained Human Action Recognition
- Log in to post comments
Fine-grained human action recognition is a core research topic in computer vision. Inspired by the recently proposed hierarchy representation of fine-grained actions in FineGym and SlowFast network for action recognition, we propose a novel multi-task network which exploits the FineGym hierarchy representation to achieve effective joint learning and prediction for fine-grained human action recognition.
- Categories:
28 Views
- Read more about Refining the bounding volumes for lossless compression of voxelized point clouds geometry
- Log in to post comments
- Categories:
36 Views
- Read more about SOLVING FOURIER PHASE RETRIEVAL WITH A REFERENCE IMAGE AS A SEQUENCE OF LINEAR INVERSE PROBLEMS
- Log in to post comments
- Categories:
20 Views
- Read more about CFPNET: CHANNEL-WISE FEATURE PYRAMID FOR REAL-TIME SEMANTIC SEGMENTATION
- Log in to post comments
Real-time semantic segmentation is playing a more important role in computer vision, due to the growing demand for mobile devices and autonomous driving. Therefore, it is very important to achieve a good trade-off among performance, model size and inference speed. In this paper, we propose a Channel-wise Feature Pyramid (CFP) module to balance those factors. Based on the CFP module, we built CFPNet for real-time semantic segmentation which applied a series of dilated convolution channels to extract effective features.
- Categories:
89 Views
- Read more about On Securing Cloud-Hosted Cyber-Physical Systems Using Trusted Execution Environments
- Log in to post comments
Recently, cloud control systems have gained increasing attention from the research community as a solution to implement networked cyber-physical systems (CPSs). Such an architecture can reduce deployment and maintenance costs albeit at the expense of additional security and privacy concerns. In this paper, first, we discuss state-of-the-art security solutions for cloud control systems and their limitations. Then, we propose a novel control architecture based on Trusted Execution Environments (TEE).
ICAS2021.pdf
- Categories:
11 Views