
DCC 2023 Conference - The Data Compression Conference (DCC) is an international forum for current work on data compression and related applications. Both theoretical and experimental work are of interest. Visit the DCC 2023 website.

- Categories:
 57 Views
57 Views
- Read more about Multiscale convolutional neural networks for in-loop video restoration
- Log in to post comments
In this paper, we consider using a multiscale approach to reduce complexity while maintaining coding efficiency. Experimental results demonstrate a 5.4× reduction in MAC operations while achieving an average bit rate savings of 6.4% and 6.3% for all intra and random access coding, respectively, when compared to the evolving AV2 standard. Ablation studies are also provided and show that the approach achieves all but 0.2% of the coding efficiency of full resolution processing.
- Categories:
89 Views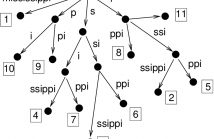
- Read more about Computing Matching Statistics on Wheeler DFAs
- Log in to post comments
Matching statistics were introduced to solve the approximate string matching problem, which is a recurrent subroutine in bioinformatics applications. In 2010, Ohlebusch et al. [SPIRE 2010] proposed a time and space efficient algorithm for computing matching statistics which relies on some components of a compressed suffix tree - notably, the longest common prefix (LCP) array.
- Categories:
84 Views
- Read more about Abstract Huffman Coding and PIFO Tree Embeddings
- Log in to post comments
Algorithms for deriving Huffman codes and the recently developed algorithm for compiling PIFO trees to trees of fixed shape [1] are similar, but work with different underlying algebraic operations. In this paper, we exploit the monadic structure of prefix codes to create a generalized Huffman algorithm that has these two applications as special cases.
- Categories:
26 Views
Deep variational autoencoders for image and video compression have gained significant attraction
in the recent years, due to their potential to offer competitive or better compression
rates compared to the decades long traditional codecs such as AVC, HEVC or VVC. However,
because of complexity and energy consumption, these approaches are still far away
from practical usage in industry. More recently, implicit neural representation (INR) based
codecs have emerged, and have lower complexity and energy usage to classical approaches at
- Categories:
88 Views
- Read more about Butterfly: Multiple Reference Frames Feature Propagation Mechanism for Neural Video Compression
- Log in to post comments
- Categories:
44 Views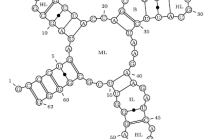
- Read more about RNA secondary structures: from ab initio prediction to better compression, and back
- Log in to post comments
In this paper, we use the biological domain knowledge incorporated into stochastic models
for ab initio RNA secondary-structure prediction to improve the state of the art in joint
compression of RNA sequence and structure data (Liu et al., BMC Bioinformatics, 2008).
Moreover, we show that, conversely, compression ratio can serve as a cheap and robust
proxy for comparing the prediction quality of different stochastic models, which may help
guide the search for better RNA structure prediction models.
- Categories:
37 Views
- Read more about Linear Computation Coding: Exponential Search and Reduced-State Algorithms
- Log in to post comments
Linear computation coding is concerned with the compression of multidimensional linear functions, i.e. with reducing the computational effort of multiplying an arbitrary vector to an arbitrary, but known, constant matrix.
This paper advances over the state-of-the art, that is based on a discrete matching pursuit (DMP) algorithm, by a step-wise optimal search.
Offering significant performance gains over DMP, it is however computationally infeasible for large matrices and high accuracy.
dcc23_lcc.pdf
- Categories:
30 Views