
MMSP 2019 is the IEEE 21st International Workshop on Multimedia Signal Processing. The workshop is organized by the Multimedia Signal Processing Technical Committee (MMSP TC) of the IEEE Signal Processing Society (SPS). The workshop will bring together researcher and developers from different fields working on multimedia signal processing to share their experience, exchange ideas, explore future research directions and network.
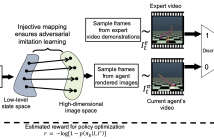
- Read more about Injective State-Image Mapping facilitates Visual Adversarial Imitation Learning
- Log in to post comments
The growing use of virtual autonomous agents in applications like games and entertainment demands better control policies for natural-looking movements and actions. Unlike the conventional approach of hard-coding motion routines, we propose a deep learning method for obtaining control policies by directly mimicking raw video demonstrations. Previous methods in this domain rely on extracting low-dimensional features from expert videos followed by a separate hand-crafted reward estimation step.
mmps_final.pdf
- Categories:
 38 Views
38 Views
- Read more about Learning Multiple Sound Source 2D Localization
- Log in to post comments
In this paper, we propose novel deep learning based algorithms for multiple sound source localization. Specifically, we aim to find the 2D Cartesian coordinates of multiple sound sources in an enclosed environment by using multiple microphone arrays. To this end, we use an encoding-decoding architecture and propose two improvements on it to accomplish the task. In addition, we also propose two novel localization representations which increase the accuracy.
- Categories:
117 Views
- Read more about End-to-End Conditional GAN-based Architectures for Image Colourisation
- Log in to post comments
In this work recent advances in conditional adversarial networks are investigated to develop an end-to-end architecture based on Convolutional Neural Networks (CNNs) to directly map realistic colours to an input greyscale image. Observing that existing colourisation methods sometimes exhibit a lack of colourfulness, this paper proposes a method to improve colourisation results. In particular, the method uses Generative Adversarial Neural Networks (GANs) and focuses on improvement of training stability to enable better generalisation in large multi-class image datasets.
- Categories:
50 Views
- Categories:
49 Views
- Read more about Semantic Segmentation in Compressed Videos
- Log in to post comments
Existing approaches for semantic segmentation in
videos usually extract each frame as an RGB image, then apply
standard image-based semantic segmentation models on each
frame. This is time-consuming. In this paper, we tackle this
problem by exploring the nature of video compression techniques.
A compressed video contains three types of frames, I-frames,
P-frames, and B-frames. I-frames are represented as regular
images, P-frames are represented as motion vectors and residual
errors, and B-frames are bidirectionally frames that can be
- Categories:
50 Views
- Read more about Youtube UGC Dataset for Video Compression Research
- Log in to post comments
This poster introduces a large scale UGC dataset (1500 20 sec video clips) sampled from millions of Creative Commons YouTube videos. The dataset covers popular categories like Gaming, Sports, and new features like High Dynamic Range (HDR). Besides a novel sampling method based on features extracted from encoding, challenges for UGC compression and quality evaluation are also discussed. Shortcomings of traditional reference-based metrics on UGC are addressed.
- Categories:
145 Views
- Read more about An Occlusion Probability Model for Improving the Rendering Quality of Views
- Log in to post comments
Occlusion as a common phenomenon in object surface can seriously affect information collection of light field. To visualize light field data-set, occlusions are usually idealized and neglected for most prior light field rendering (LFR) algorithms. However, the 3D spatial structure of some features may be missing to capture some incorrect samples caused by occlusion discontinuities. To solve this problem, we propose an occlusion probability (OCP) model to improve the capturing information and the rendering quality of views with occlusion for the LFR.
- Categories:
27 Views
- Read more about EVS AND OPUS AUDIO CODERS PERFORMANCE EVALUATION FOR ORIENTAL AND ORCHESTRAL MUSICAL INSTRUMENTS
- Log in to post comments
In modern telecommunication systems the channel bandwidth and the quality of the reconstructed decoded audio signals are considered as major telecommunication resources. New speech or audio coders must be carefully designed and implemented to meet these requirements. EVS and OPUS audio coders are new coders which used to improve the quality of the reconstructed audio signal at different output bitrates. These coders can operate with different input signal type. The performance of these coders must be evaluated in terms of the quality of the reconstructed signals.
- Categories:
78 Views
- Read more about Discrete Cosine Basis Oriented Motion Modeling for Fisheye and 360 Degree Video Coding
- Log in to post comments
Motion modeling plays a central role in video compression. This role is even more critical in fisheye video sequences
since the wide-angle fisheye imagery has special characteristics as in exhibiting radial distortion. While the translational motion model employed by modern video coding standards, such as HEVC, is sufficient in most cases, using higher order models is
beneficial; for this reason, the upcoming video coding standard, VVC, employs a 4-parameter affine model. Discrete cosine basis
- Categories:
17 Views