
- Read more about Exploring Phonetic Context-Aware Lip-Sync For Talking Face Generation
- Log in to post comments
Talking face generation is the challenging task of synthesizing a natural and realistic face that requires accurate synchronization with a given audio. Due to co-articulation, where an isolated phone is influenced by the preceding or following phones, the articulation of a phone varies upon the phonetic context. Therefore, modeling lip motion with the phonetic context can generate more spatio-temporally aligned lip movement. In this respect, we investigate the phonetic context in generating lip motion for talking face generation.
- Categories:
 16 Views
16 Views
- Read more about Multiscale Audio Spectrogram Transformer for Efficient Audio Classification
- Log in to post comments
Audio event has a hierarchical architecture in both time and frequency and can be grouped together to construct more abstract semantic audio classes. In this work, we develop a multiscale audio spectrogram Transformer (MAST) that employs hierarchical representation learning for efficient audio classification. Specifically, MAST employs one-dimensional (and two-dimensional) pooling operators along the time (and frequency domains) in different stages, and progressively reduces the number of tokens and increases the feature dimensions.
- Categories:
45 Views
- Categories:
108 Views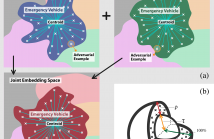
- Read more about On Adversarial Robustness of Large-scale Audio Visual Learning
- 1 comment
- Log in to post comments
- Categories:
31 Views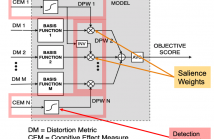
- Read more about A Data-driven Cognitive Salience Model for Objective Perceptual Audio Quality Assessment
- Log in to post comments
Objective audio quality assessment systems often use perceptual models to predict the subjective quality scores of processed signals, as reported in listening tests. Most systems map different metrics of perceived degradation into a single quality score predicting subjective quality. This requires a quality mapping stage that is informed by real listening test data using statistical learning (\iec a data-driven approach) with distortion metrics as input features.
- Categories:
81 Views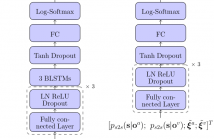
- Read more about Fusing Information Streams in End-to-End Audio-Visual Speech Recognition
- Log in to post comments
End-to-end acoustic speech recognition has quickly gained widespread popularity and shows promising results in many studies. Specifically the joint transformer/CTC model provides very good performance in many tasks. However, under noisy and distorted conditions, the performance still degrades notably. While audio-visual speech recognition can significantly improve the recognition rate of end-to-end models in such poor conditions, it is not obvious how to best utilize any available information on acoustic and visual signal quality and reliability in these models.
- Categories:
13 Views
- Read more about Translation of a Higher Order Ambisonics Sound Scene Based on Parametric Decomposition
- Log in to post comments
This paper presents a novel 3DoF+ system that allows to navigate, i.e., change position, in scene-based spatial audio content beyond the sweet spot of a Higher Order Ambisonics recording. It is one of the first such systems based on sound capturing at a single spatial position. The system uses a parametric decomposition of the recorded sound field. For the synthesis, only coarse distance information about the sources is needed as side information but not the exact number of them.
handout.pdf
- Categories:
86 Views
- Read more about Wav2Pix: Speech-conditioned Face Generation using Generative Adversarial Networks
- Log in to post comments
Speech is a rich biometric signal that contains information about the identity, gender and emotional state of the speaker. In this work, we explore its potential to generate face images of a speaker by conditioning a Generative Adversarial Network (GAN) with raw speech input. We propose a deep neural network that is trained from scratch in an end-to-end fashion, generating a face directly from the raw speech waveform without any additional identity information (e.g reference image or one-hot encoding).
- Categories:
102 Views
- Read more about A Comparison of Five Multiple Instance Learning Pooling Functions for Sound Event Detection with Weak Labeling
- Log in to post comments
Sound event detection (SED) entails two subtasks: recognizing what types of sound events are present in an audio stream (audio tagging), and pinpointing their onset and offset times (localization). In the popular multiple instance learning (MIL) framework for SED with weak labeling, an important component is the pooling function. This paper compares five types of pooling functions both theoretically and experimentally, with special focus on their performance of localization.
- Categories:
13 Views
- Read more about Connectionist Temporal Localization for Sound Event Detection with Sequential Labeling
- Log in to post comments
Research on sound event detection (SED) with weak labeling has mostly focused on presence/absence labeling, which provides no temporal information at all about the event occurrences. In this paper, we consider SED with sequential labeling, which specifies the temporal order of the event boundaries. The conventional connectionist temporal classification (CTC) framework, when applied to SED with sequential labeling, does not localize long events well due to a "peak clustering" problem.
Poster.pdf
- Categories:
14 Views