
- Read more about DEEP FEATURES BASED ON CONTRASTIVE FUSION OF TRANSFORMER AND CNN FOR SEMANTIC SEGMENTATION
- Log in to post comments
Image segmentation plays a crucial role in various computer vision applications for accurately identifying and extracting objects or regions of interest within an image. Despite significant advancements in state-of-the-art (SOTA) models for semantic segmentation, many still rely on additional and huge datasets to improve their performance.
- Categories:
 57 Views
57 Views
- Read more about Learning From PU Data Using Disentangled Representations [Supplemental Material]
- Log in to post comments
We address the problem of learning a binary classifier given partially labeled data where all labeled samples come from only one of the classes, commonly known as Positive Unlabeled (PU) learning. Classical methods such as clustering, out-of-distribution detection, and positive density estimation, while effective in low-dimensional scenarios, lose their efficacy as the dimensionality of data increases, because of the increasing complexity.
- Categories:
12 Views
- Read more about MAP-YNET: LEARNING FROM FOUNDATION MODELS FOR REAL-TIME, MULTI-TASK SCENE PERCEPTION
- Log in to post comments
This is video and qualitative supplementary material for ICIP 2025
- Categories:
13 Views
VIEWPOINT-DEPENDENT 3D VISUAL GROUNDING FOR MOBILE ROBOTS
SUPPLEMENTARY MATERIAL
- Categories:
66 Views
- Read more about Multimodal-Enhanced Objectness Learner for Corner Case Detection in Autonomous Driving
- 1 comment
- Log in to post comments
Previous works on object detection have achieved high accuracy in closed-set scenarios, but their performance in open-world scenarios is not satisfactory. One of the challenging open-world problems is corner case detection in autonomous driving. Existing detectors struggle with these cases, relying heavily on visual appearance and exhibiting poor generalization ability. In this paper, we propose a solution by reducing the discrepancy between known and unknown classes and introduce a multimodal-enhanced objectness notion learner.
- Categories:
29 Views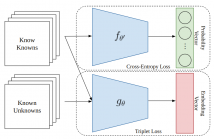
- Read more about CASCADING UNKNOWN DETECTION WITH KNOWN CLASSIFICATION FOR OPEN SET RECOGNITION
- Log in to post comments
Deep learners tend to perform well when trained under the closed set assumption but struggle when deployed under open set conditions. This motivates the field of Open Set Recognition in which we seek to give deep learners the ability to recognize whether a data sample belongs to the known classes trained on or comes from the surrounding infinite world. Existing open set recognition methods typically rely upon a single function for the dual task of distinguishing between knowns and unknowns as well as making known class distinction.
- Categories:
25 Views- Read more about TOWARDS MULTI-DOMAIN FACE LANDMARK DETECTION WITH SYNTHETIC DATA FROM DIFFUSION MODEL
- Log in to post comments
Recently, deep learning-based facial landmark detection for in-the-wild faces has achieved significant improvement. However, there are still challenges in face landmark detection in other domains (\eg{} cartoon, caricature, etc). This is due to the scarcity of extensively annotated training data. To tackle this concern, we design a two-stage training approach that effectively leverages limited datasets and the pre-trained diffusion model to obtain aligned pairs of landmarks and face in multiple domains.
- Categories:
32 Views
- Read more about CAG-FPN: CHANNEL SELF-ATTENTION GUIDED FEATURE PYRAMID NETWORK FOR OBJECT DETECTION
- 1 comment
- Log in to post comments
Feature Pyramid Network (FPN) plays a critical role and is indispensable for object detection methods. In recent years, attention mechanism has been utilized to improve FPN due to its excellent performance. Existing attention-based FPN methods generally work with a complex structure, resulting in an increase of computational costs. In view of this, we propose a novel Channel Self-Attention Guided Feature Pyramid Network (CAG-FPN), which not only has a simple structure but also consistently improves detection accuracy.
- Categories:
47 Views- Read more about A Parameterized Generative Adversarial Network Using Cyclic Projection for Explainable Medical Image Classification
- Log in to post comments
Although current data augmentation methods are successful to alleviate the data insufficiency, conventional augmentation are primarily intra-domain while advanced generative adversarial networks (GANs) generate images remaining uncertain, particularly in small-scale datasets. In this paper, we propose a parameterized GAN (ParaGAN) that effectively controls the changes of synthetic samples among domains and highlights the attention regions for downstream classification.
- Categories:
15 Views
- Read more about DELVING DEEPER INTO VULNERABLE SAMPLES IN ADVERSARIAL TRAINING
- Log in to post comments
Recently, vulnerable samples have been shown to be crucial
for improving adversarial training performance. Our analysis
on existing vulnerable samples mining methods indicate that
existing methods have two problems: 1) valuable connections
among different pairs of natural samples and their adversarial
counterparts are ignored; 2) parts of vulnerable samples are
unconsidered. To better leverage vulnerable samples, we propose INter PAir ConstrainT (INPACT) and Vulnerable Aware
poster.pptx
- Categories:
21 Views