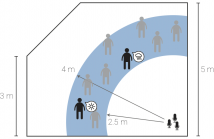
It is commonly believed that multipath hurts various audio processing algorithms. At odds with this belief, we show that multipath in fact helps sound source separation, even with very simple propagation models. Unlike most existing methods, we neither ignore the room impulse responses, nor we attempt to estimate them fully. We rather assume to know the positions of a few virtual microphones generated by echoes and we show how this gives us enough spatial diversity to get a performance boost over the anechoic case.
- Categories:
 78 Views
78 Views
- Read more about ADAPTIVE CODING OF NON-NEGATIVE FACTORIZATION PARAMETERS WITH APPLICATION TO INFORMED SOURCE SEPARATION
- Log in to post comments
Informed source separation (ISS) uses source separation for extracting audio objects out of their downmix given some pre-computed parameters. In recent years, non-negative tensor factorization (NTF) has proven to be a good choice for compressing audio objects at an encoding stage. At the decoding stage, these parameters are used to separate the downmix with Wiener-filtering. The quantized NTF parameters have to be encoded to a bitstream prior to transmission.
- Categories:
15 Views
- Read more about Shift-Invariant Kernel Additive Modelling for Audio Source Separation
- 1 comment
- Log in to post comments
A major goal in blind source separation to identify and separate sources is to model their inherent characteristics. While most state-of- the-art approaches are supervised methods trained on large datasets, interest in non-data-driven approaches such as Kernel Additive Modelling (KAM) remains high due to their interpretability and adaptability. KAM performs the separation of a given source applying robust statistics on the time-frequency bins selected by a source-specific kernel function, commonly the K-NN function.
dfy_poster.pdf
- Categories:
10 Views
- Read more about END-TO-END SOUND SOURCE ENHANCEMENT USING DEEP NEURAL NETWORK IN THE MODIFIED DISCRETE COSINE TRANSFORM DOMAIN
- Log in to post comments
- Categories:
36 Views
- Read more about ON SPEECH ENHANCEMENT USING MICROPHONE ARRAYS IN THE PRESENCE OF CO-DIRECTIONAL INTERFERENCE
- Log in to post comments
- Categories:
27 Views
- Read more about SINGLE CHANNEL SPEECH SEPARATION WITH CONSTRAINED UTTERANCE LEVEL PERMUTATION INVARIANT TRAINING USING GRID LSTM
- Log in to post comments
Utterance level permutation invariant training (uPIT) tech- nique is a state-of-the-art deep learning architecture for speaker independent multi-talker separation. uPIT solves the label ambiguity problem by minimizing the mean square error (MSE) over all permutations between outputs and tar- gets. However, uPIT may be sub-optimal at segmental level because the optimization is not calculated over the individual frames. In this paper, we propose a constrained uPIT (cu- PIT) to solve this problem by computing a weighted MSE loss using dynamic information (i.e., delta and acceleration).
- Categories:
86 Views
- Read more about Language and Noise Transfer in Speech Enhancement Generative Adversarial Network
- Log in to post comments
Speech enhancement deep learning systems usually require large amounts of training data to operate in broad conditions or real applications. This makes the adaptability of those systems into new, low resource environments an important topic. In this work, we present the results of adapting a speech enhancement generative adversarial network by fine-tuning the generator with small amounts of data. We investigate the minimum requirements to obtain a stable behavior in terms of several objective metrics in two very different languages: Catalan and Korean.
- Categories:
5 Views
- Read more about Language and Noise Transfer in Speech Enhancement Generative Adversarial Network
- Log in to post comments
Speech enhancement deep learning systems usually require large amounts of training data to operate in broad conditions or real applications. This makes the adaptability of those systems into new, low resource environments an important topic. In this work, we present the results of adapting a speech enhancement generative adversarial network by fine-tuning the generator with small amounts of data. We investigate the minimum requirements to obtain a stable behavior in terms of several objective metrics in two very different languages: Catalan and Korean.
- Categories:
11 Views
- Read more about ESTIMATION OF THE SOUND FIELD AT ARBITRARY POSITIONS IN DISTRIBUTED MICROPHONE NETWORKS BASED ON DISTRIBUTED RAY SPACE TRANSFORM
- Log in to post comments
- Categories:
20 Views
We propose an end-to-end model based on convolutional and recurrent neural networks for speech enhancement. Our model is purely data-driven and does not make any assumptions about the type or the stationarity of the noise. In contrast to existing methods that use multilayer perceptrons (MLPs), we employ both convolutional and recurrent neural network architectures. Thus, our approach allows us to exploit local structures in both the frequency and temporal domains.
- Categories:
43 Views