
ICASSP is the world's largest and most comprehensive technical conference on signal processing and its applications. It provides a fantastic networking opportunity for like-minded professionals from around the world. ICASSP 2016 conference will feature world-class presentations by internationally renowned speakers and cutting-edge session topics.
- Read more about ON THE DETECTION OF NON-STATIONARY SIGNALS IN THE MATCHED SIGNAL TRANSFORM DOMAIN
- Log in to post comments
- Categories:
 6 Views
6 Views- Read more about Partial Face Recognition: A Sparse Representation-based Approach
- Log in to post comments
Partial face recognition is a problem that often arises in practical settings and applications. We propose a sparse representation-based algorithm for this problem. Our method firstly trains a dictionary and the classifier parameters in a supervised dictionary learning framework and then aligns the partially observed test image and seeks for the sparse representation with respect to the training data alternatively to obtain its label. We also analyze the performance limit of sparse representation-based classification algorithms on partial observations.
- Categories:
31 Views
- Read more about Classification Of Respiratory Effort And Disordered Breathing During Sleep From Audio and Pulse Oximetry Signals
- Log in to post comments
Sleep-disordered breathing (SDB) is a highly prevalent condition associated with many adverse health problems. As the current means of diagnosis (polysomnography) is obtrusive and ill-suited for mass screening of the population, we explore a minimal-contact, automatic approach that uses acoustics-based methods in conjunction with pulse oximetry. We present a two-stage method for automatically classifying breathing sounds produced during sleep to track respiratory effort and predicting disordered breathing events using respiratory effort durations and oxygen desaturations.
icassp2016.pdf
- Categories:
25 Views
- Read more about Template based techniques for automatic segmentation of TTS unit database
- Log in to post comments
Template based automatic segmentation of unit-database for TTS into phonetic and syllabic units.
- Categories:
15 Views
- Read more about A Bayesian framework for the multifractal analysis of images using data augmentation and a Whittle approximation
- Log in to post comments
Texture analysis is an image processing task that can be conducted using the mathematical framework of multifractal analysis to study the regularity fluctuations of image intensity and the practical tools for their assessment, such as (wavelet) leaders. A recently introduced statistical model for leaders enables the Bayesian estimation of multifractal parameters. It significantly improves performance over standard (linear regression based) estimation. However, the computational cost induced by the associated nonstandard posterior distributions limits its application.
- Categories:
18 Views
- Read more about Deep Unfolding for Multichannel Source Separation
- Log in to post comments
Deep unfolding has recently been proposed to derive novel deep network architectures from model-based approaches. In this paper, we consider its application to multichannel source separation. We unfold a multichannel Gaussian mixture model (MCGMM), resulting in a deep MCGMM computational network that directly processes complex-valued frequency-domain multichannel audio and has an architecture defined explicitly by a generative model, thus combining the advantages of deep networks and model-based approaches.
- Categories:
198 Views- Read more about Predicting Visual Attention Using Gamma Kernels
- Log in to post comments
Saliency measures are a popular way to predict visual attention. However, saliency is normally tested on sets of single resolution images that are unlike what the human vision system sees. We propose a new saliency measure based on convolving images with 2D gamma kernels which function as a comparison between a center and a surrounding neighborhood. The two parameters in the gamma kernel provide an ideal way to change the size of both the center and the surrounding neighborhood, which makes finding saliency at different scales simple and fast.
- Categories:
12 Views
Nowadays, with the success and fast growth of social media communities and mobile devices, people are encouraged to share their multimedia data online. Analyzing and summarizing data into useful information thus becomes increasingly important. For on- line photo sharing services like Flickr, when users are uploading a batch of daily photos at a time, the tags users provided tend to be rather vague, containing only a small amount of information.
- Categories:
19 Views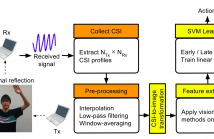
- Read more about WiFi Action Recognition via Vision based Methods
- Log in to post comments
Action recognition via WiFi has caught intense attention recently because of its ubiquity, low cost, and privacy- preserving. Observing Channel State Information (CSI, a fine-grained information computed from the received WiFi signal) resemblance to texture, we transform the received CSI into images, extract features with vision-based methods and train SVM classifiers for action recognition. Our experiments show that regarding CSI as images achieves an accuracy above 85%. Our contributions include:
- Categories:
20 Views