
ICASSP is the world's largest and most comprehensive technical conference on signal processing and its applications. It provides a fantastic networking opportunity for like-minded professionals from around the world. ICASSP 2016 conference will feature world-class presentations by internationally renowned speakers and cutting-edge session topics.
- Read more about AN ALTERNATIVE APPROACH FOR AUDITORY ATTENTION TRACKING USING SINGLE-TRIAL EEG
- Log in to post comments
Auditory selective attention plays a central role in the human capacity to reliably process complex sounds in multi-source environments. Stimulus reconstruction has been widely used for the investigation of selective auditory attention using multichannel electroencephalography (EEG). In particular, the influence of attention on sound representations in the brain has been modeled by linear time-variant filters and have been used to track the attentional state of individuals in multi-source environments.
- Categories:
 29 Views
29 Views- Read more about Mood State Prediction from Speech of Varying Acoustic Quality for Individuals with Bipolar Disorder
- Log in to post comments
Speech contains patterns that can be altered by the mood of an individual. There is an increasing focus on automated and distributed methods to collect and monitor speech from large groups of patients suffering from mental health disorders. However, as the scope of these collections increases, the variability in the data also increases. This variability is due in part to the range in the quality of the devices, which in turn affects the quality of the recorded data, negatively impacting the accuracy of automatic assessment.
- Categories:
14 Views- Read more about Multicore Implementation of LDPC Decoders based on ADMM Algorithm
- Log in to post comments
Alternate direction method of multipliers (ADMM) technique has re- cently been proposed for LDPC decoding. Even though it improves the error rate performance compared with traditional message pass- ing (MP) techniques, it shows a higher computation complexity. In this article, the ADMM decoding algorithm is first described. Then, its computation complexity is analyzed. Finally, an optimized ver- sion which benefits from the multi-core processors architecture as well as the ADMM algorithm’s parallelism is presented.
- Categories:
22 Views
- Read more about Super Nested Arrays: Sparse Arrays with Less Mutual Coupling Than Nested Arrays
- Log in to post comments
In array processing, mutual coupling between sensors has an adverse effect on the estimation of parameters (e.g., DOA). Sparse arrays, such as nested arrays, coprime arrays, and minimum redundancy arrays (MRAs), have reduced mutual coupling compared to uniform linear arrays (ULAs). With $N$ denoting the number of sensors, these sparse arrays offer $O(N^2)$ freedoms for source estimation because their difference coarrays have $O(N^2)$-long ULA segments.
- Categories:
37 Views- Read more about CONTINUOUS ULTRASOUND BASED TONGUE MOVEMENT VIDEO SYNTHESIS FROM SPEECH
- Log in to post comments
The movement of tongue plays an important role in pronunciation. Visualizing the movement of tongue can improve speech intelligibility and also helps learning a second language. However, hardly any research has been investigated for this topic. In this paper, a framework to synthesize continuous ultrasound tongue movement video from speech is presented. Two different mapping methods are introduced as the most important parts of the framework.
- Categories:
7 Views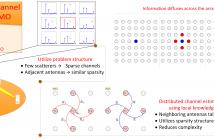
- Read more about Efficient Coordinated Recovery of Sparse Channels in Massive MIMO
- Log in to post comments
We tackle the problem of estimating sparse channels in massive MIMO-OFDM systems.
The code of our algorithms could be downloaded from Prof. Tareq Al-Naffouri's website http://faculty.kfupm.edu.sa/ee/naffouri/publications/demo_massiveMIMO.zip (617)
or from MATLAB File Exchange http://goo.gl/P19F1Y
- Categories:
42 Views- Read more about FREQUENCY-BASED CUSTOMIZATION OF MULTIZONE SOUND SYSTEM DESIGN
- Log in to post comments
- Categories:
1 Views- Read more about FREQUENCY-BASED CUSTOMIZATION OF MULTIZONE SOUND SYSTEM DESIGN
- Log in to post comments
- Categories:
4 Views