
ICASSP is the world's largest and most comprehensive technical conference on signal processing and its applications. It provides a fantastic networking opportunity for like-minded professionals from around the world. ICASSP 2017 conference will feature world-class presentations by internationally renowned speakers and cutting-edge session topics. Visit ICASSP 2017
In this paper we describe approaches for discovering acoustic concepts and relations in text. The first major goal is to be able to identify text phrases which contain a notion of audibility and can be termed as a sound or an acoustic concept. We also propose a method to define an acoustic scene through a set of sound concepts. We use pattern matching and parts of speech tags to generate sound concepts from large scale text corpora. We use dependency parsing
- Categories:
 16 Views
16 Views- Read more about Exemplar‐Embed Complex Matrix Factorization for Facial Expression Recognition
- Log in to post comments
- Categories:
17 Views
- Read more about Symbol Detection for Faster-than-Nyquist Signaling by Sum-of-Absolute-Values Optimization
- Log in to post comments
In this work, we propose a new symbol detection method in faster-than-Nyquist signaling for effective data transmission. Based on the frame theory, the symbol detection problem is described as under-determined linear equations on a finite alphabet. While the problem is itself NP (non-deterministic polynomial-time) hard, we propose convex relaxation using the sum-of-absolute-values optimization, which can be efficiently solved by proximal splitting. Simulation results are shown to illustrate the effectiveness of the proposed method compared to a recent ell-infinity-based method.
- Categories:
37 Views- Read more about A First Attempt at Polyphonic Sound Event Detection Using Connectionist Temporal Classification
- Log in to post comments
Sound event detection is the task of detecting the type, starting time, and ending time of sound events in audio streams. Recently, recurrent neural networks (RNNs) have become the mainstream solution for sound event detection. Because RNNs make a prediction at every frame, it is necessary to provide exact starting and ending times of the sound events in the training data, making data annotation an extremely time-consuming process.
- Categories:
12 Views
- Read more about INTERAURAL TIME DELAY PERSONALISATION USING INCOMPLETE HEAD SCANS
- Log in to post comments
When using a set of generic head-related transfer functions (HRTFs) for spatial sound rendering, personalisation can be considered to minimise localisation errors. This typically involves tuning the characteristics of the HRTFs or a parametric model according to the listener’s anthropometry. However, measuring anthropometric features directly remains a challenge in practical applications, and the mapping between anthropometric and acoustic features is an open research problem.
- Categories:
15 Views- Read more about BAYESIAN RECONSTRUCTION OF HYPERSPECTRAL IMAGES BY USING COMPRESSED SENSING MEASUREMENTS AND A LOCAL STRUCTURED PRIOR
- Log in to post comments
This paper introduces a hierarchical Bayesian model for the reconstruction of hyperspectral images using compressed sensing measurements. This model exploits known properties of natural images, promoting the recovered image to be sparse on a selected basis and smooth in the image domain. The posterior distribution of this model is too complex to derive closed form expressions for the estimators of its parameters. Therefore, an MCMC method is investigated to sample this posterior distribution.
- Categories:
16 Views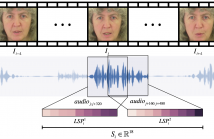
Speechreading is a notoriously difficult task for humans to perform. In this paper we present an end-to-end model based on a convolutional neural network (CNN) for generating an intelligible acoustic speech signal from silent video frames of a speaking person. The proposed CNN generates sound features for each frame based on its neighboring frames. Waveforms are then synthesized from the learned speech features to produce intelligible speech.
- Categories:
26 Views- Read more about DETECTION OF IMPULSIVE DISTURBANCES IN ARCHIVE AUDIO SIGNALS
- Log in to post comments
The problem of detection of impulsive disturbances in archive audio signals is considered. It is shown that semi-causal/noncausal solutions based on joint evaluation of signal prediction errors and leave-one-out signal interpolation errors, allow one to noticeably improve detection results compared to the prediction-only based solutions. The proposed approaches are evaluated on a set of clean audio signals contaminated with real click waveforms extracted from silent parts of old gramophone recordings.
- Categories:
10 Views- Read more about Statistical Normalisation of Phase-based Feature Representation for Robust Speech Recognition
- Log in to post comments
In earlier work we have proposed a source-filter decomposition of
speech through phase-based processing. The decomposition leads
to novel speech features that are extracted from the filter component
of the phase spectrum. This paper analyses this spectrum and the
proposed representation by evaluating statistical properties at vari-
ous points along the parametrisation pipeline. We show that speech
phase spectrum has a bell-shaped distribution which is in contrast to
the uniform assumption that is usually made. It is demonstrated that
- Categories:
12 Views