
ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The 2019 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit website.
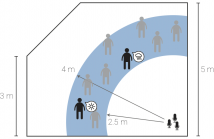
It is commonly believed that multipath hurts various audio processing algorithms. At odds with this belief, we show that multipath in fact helps sound source separation, even with very simple propagation models. Unlike most existing methods, we neither ignore the room impulse responses, nor we attempt to estimate them fully. We rather assume to know the positions of a few virtual microphones generated by echoes and we show how this gives us enough spatial diversity to get a performance boost over the anechoic case.
- Categories:
 78 Views
78 Views
- Read more about A DEEPER LOOK AT GAUSSIAN MIXTURE MODEL BASED ANTI-SPOOFING SYSTEMS
- Log in to post comments
- Categories:
37 Views
- Read more about ADAPTIVE CODING OF NON-NEGATIVE FACTORIZATION PARAMETERS WITH APPLICATION TO INFORMED SOURCE SEPARATION
- Log in to post comments
Informed source separation (ISS) uses source separation for extracting audio objects out of their downmix given some pre-computed parameters. In recent years, non-negative tensor factorization (NTF) has proven to be a good choice for compressing audio objects at an encoding stage. At the decoding stage, these parameters are used to separate the downmix with Wiener-filtering. The quantized NTF parameters have to be encoded to a bitstream prior to transmission.
- Categories:
16 Views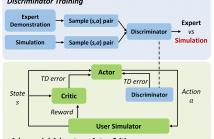
- Read more about Adversarial Advantage Actor-Critic Model for Task-Completion Dialogue Policy Learning
- Log in to post comments
This paper presents a new method --- adversarial advantage actor-critic (Adversarial A2C), which significantly improves the efficiency of dialogue policy learning in task-completion dialogue systems. Inspired by generative adversarial networks (GAN), we train a discriminator to differentiate responses/actions generated by dialogue agents from responses/actions by experts.
- Categories:
59 Views
- Read more about AN IMPROVED DOA ESTIMATOR BASED ON PARTIAL RELAXATION APPROACH
- Log in to post comments
In the partial relaxation approach, at each desired direction, the manifold structure of the remaining interfering signals impinging on the sensor array is relaxed, which results in closed form estimates for the interference parameters. By adopting this approach, in this paper, a new estimator based on the unconstrained covariance fitting problem is proposed. To obtain the null-spectra efficiently, an iterative rooting scheme based on the rational function approximation is applied.
- Categories:
15 Views
- Read more about A 203 FPS VLSI ARCHITECTURE OF IMPROVED DENSE TRAJECTORIES FOR REAL-TIME HUMAN ACTION RECOGNITION
- Log in to post comments
This paper introduces architecture with high throughput, low on-chip memory, and efficient data access for Improved Dense Trajectories (iDT) as video representations for real-time action recognition. The iDT feature can capture long-term motion cues better than any existing deep feature, which makes it crucial in state-of-the-art action recognition systems.
- Categories:
15 Views
- Read more about A HYBRID NEURAL NETWORK BASED ON THE DUPLEX MODEL OF PITCH PERCEPTION FOR SINGING MELODY EXTRACTION
- Log in to post comments
In this paper, we build up a hybrid neural network (NN) for singing melody extraction from polyphonic music by imitating human pitch perception. For human hearing, there are two pitch perception models, the spectral model and the temporal model, in accordance with whether harmonics are resolved or not. Here, we first use NNs to implement individual models and evaluate their performance in the task of singing melody extraction.
- Categories:
32 Views
- Read more about A generative auditory model embedded neural network for speech processing
- Log in to post comments
Before the era of the neural network (NN), features extracted from auditory models have been applied to various speech applications and been demonstrated more robust against noise than conventional speech-processing features. What's the role of auditory models in the current NN era? Are they obsolete? To answer this question, we construct a NN with a generative auditory model embedded to process speech signals.
- Categories:
6 Views
- Read more about A generative auditory model embedded neural network for speech processing
- Log in to post comments
Before the era of the neural network (NN), features extracted from auditory models have been applied to various speech applications and been demonstrated more robust against noise than conventional speech-processing features. What’s the role
of auditory models in the current NN era? Are they obsolete?
To answer this question, we construct a NN with a generative auditory model embedded to process speech signals. The
generative auditory model consists of two stages, the stage of spectrum estimation in the logarithmic-frequency axis by
- Categories:
40 Views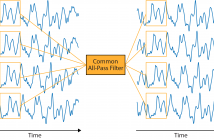
- Read more about Time-Varying Delay Estimation using Common Local All-Pass Filters with Application to Surface Electromyography
- Log in to post comments
Estimation of conduction velocity (CV) is an important task in the analysis of surface electromyography (sEMG). The problem can be framed as estimation of a time-varying delay (TVD) between electrode recordings. In this paper we present an algorithm which incorporates information from multiple electrodes into a single TVD estimation. The algorithm uses a common all-pass filter to relate two groups of signals at a local level.
- Categories:
18 Views