
The International Conference on Image Processing (ICIP), sponsored by the IEEE Signal Processing Society, is the premier forum for the presentation of technological advances and research results in the fields of theoretical, experimental, and applied image and video processing. ICIP has been held annually since 1994, brings together leading engineers and scientists in image and video processing from around the world. Visit website.

- Read more about Unconstrained Flood Event Detection Using Adversarial Data Augmentation
- Log in to post comments
Nowadays, the world faces extreme climate changes, resulting in an increase of natural disaster events and their severities. In these conditions, the necessity of disaster information management systems has become more imperative. Specifically, in this paper, the problem of flood event detection from images with real-world conditions is addressed. That is, the images may be taken in several conditions, including day, night, blurry, clear, foggy, rainy, different lighting conditions, etc. All these abnormal scenarios significantly reduce the performance of the learning algorithms.
- Categories:
 41 Views
41 Views
- Read more about Rotation-Invariant CNN using scattering transform for image classification
- Log in to post comments
ICIP_v1.pdf
- Categories:
18 Views
- Read more about AN AFFINE-LINEAR INTRA PREDICTION WITH COMPLEXITY CONSTRAINTS
- 1 comment
- Log in to post comments
This paper presents a novel method for a data-driven training of
affine-linear predictors which perform intra prediction in state-ofthe-
art video coding. The main aspect of our training design is the
use of subband decomposition of both the input and the output of the
prediction. Due to this architecture, the same set of predictors can be
shared across different block shapes leading to a very limited memory
requirement. Also, the computational complexity of the resulting
predictors can be limited such that it does not exceed the complexity
- Categories:
29 Views
- Read more about SMART: A SENSOR-TRIGGERRED INTERACTIVE MR DISPLAY
- Log in to post comments
In this paper, a prototype with a hologram display is developed as an interactive MR device, triggered by the sensor values on mobile devices to change the attitude of a virtual object in the virtual world and the real object in a physical world with a synchronizing manner. To provide a consistent displaying content from a physical world to a virtual world in an MR environment, a hologram device with a controlling mobile devices is developed.
- Categories:
13 Views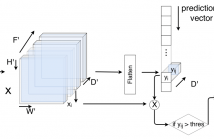
- Read more about SALIENCY TUBES: VISUAL EXPLANATIONS FOR SPATIO-TEMPORAL CONVOLUTIONS
- Log in to post comments
Deep learning approaches have been established as the main methodology for video classification and recognition. Recently, 3-dimensional convolutions have been used to achieve state-of-the-art performance in many challenging video datasets. Because of the high level of complexity of these methods, as the convolution operations are also extended to an additional dimension in order to extract features from it as well, providing a visualization for the signals that the network interpret as informative, is a challenging task.
- Categories:
29 Views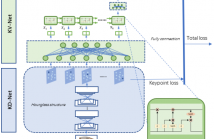
- Read more about VIEWPOINT ESTIMATION IN IMAGES BY A KEY-POINT BASED DEEP NEURAL NETWORK
- Log in to post comments
Viewpoint estimation in a 2D image is a challenging task due to the great variations in the object’s shape, appearance,
visible parts, etc. To overcome the above difficulties, a new deep neural network is proposed, which employs the key-points of the object as a regularization term and a semantic bridge connecting the raw pixels with the object’s viewpoint. A series of Hourglass structures are adopted for key-point
- Categories:
33 Views
In this paper, we propose a novel thermal face recognition based on physiological information. The training phase includes preprocessing, feature extraction and classification. In the beginning, the human face can be depicted from the background of thermal image using the Bayesian framework and normalized to uniform size. A grid of 22 thermal points is extracted as a feature vector. These 22 extracted points are used to train Linear Support Vector Machine Classifier (linear SVC). The classifier calculates the support vectors and uses them to find the hyperplane for classification.
- Categories:
22 Views
- Read more about EFFICIENT CODING OF 360° VIDEOS EXPLOITING INACTIVE REGIONS IN PROJECTION FORMATS
- Log in to post comments
This paper presents an efficient method for encoding common projection formats in 360◦ video coding, in which we exploit inactive regions. These regions are ignored in the reconstruction of the equirectangular format or the viewport in virtual reality applications. As the content of these pixels is irrelevant, we neglect the corresponding pixel values in ratedistortion optimization, residual transformation, as well as inloop filtering and achieve bitrate savings of up to 10%.
poster04.pptx
- Categories:
27 Views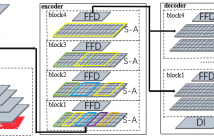
- Read more about TEXT RECOGNITION IN IMAGES BASED ON TRANSFORMER WITH HIERARCHICAL ATTENTION
- Log in to post comments
Recognizing text in images has been a hot research topic in computer vision for decades due to its various application. However, the variations in text appearance in term of perspective distortion, text line curvature, text styles, etc., cause great trouble in text recognition. Inspired by the Transformer structure that achieved outstanding performance in many natural language processing related applications, we propose a new Transformer-like structure for text recognition in images, which is referred to as the Hierarchical Attention Transformer Network (HATN).
- Categories:
107 Views
- Read more about End-To-End Visual Place Recognition Based on Deep Metric Learning and Self-Adaptively Enhanced Similarity Metric
- Log in to post comments
- Categories:
28 Views