
We summarise previous work showing that the basic sigmoid activation function arises as an instance of Bayes’s theorem, and that recurrence follows from the prior. We derive a layer- wise recurrence without the assumptions of previous work, and show that it leads to a standard recurrence with modest modifications to reflect use of log-probabilities. The resulting architecture closely resembles the Li-GRU which is the current state of the art for ASR. Although the contribution is mainly theoretical, we show that it is able to outperform the state of the art on the TIMIT and AMI datasets.
- Categories:
 24 Views
24 Views
- Read more about INTEGRATED CLASSIFICATION AND LOCALIZATION OF TARGETS USING BAYESIAN FRAMEWORK IN AUTOMOTIVE RADARS
- Log in to post comments
Automatic radar based classification of automotive targets, such as pedestrians and cyclist, poses several challenges due to low inter-class variations among different classes and large intra-class variations. Further, different targets required to track in typical automotive scenario can have completely varying dynamics which gets challenging for tracker using conventional state vectors. Compared to state-of-the-art using independent classification and tracking, in this paper, we propose an integrated tracker and classifier leading to a novel Bayesian framework.
- Categories:
7 Views
- Read more about Low-Complexity Parameter Learning for OTFS Modulation Based Automotive Radar
- Log in to post comments
Orthogonal time frequency space (OTFS) as an emerging modulation technique in the 5G and beyond era exploits full time-frequency diversity and is robust against doubly-selective channels in high mobility scenarios. In this work, we consider an OTFS modulation based automotive joint radar-communication system and focus on the design of low-complexity parameter estimation algorithm for radar targets.
- Categories:
36 Views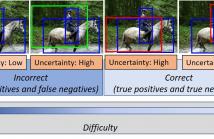
- Read more about LOSS RESCALING BY UNCERTAINTY INFERENCE FOR SINGLE-STAGE OBJECT DETECTION
- Log in to post comments
- Categories:
42 Views
- Read more about State-space Gaussian Process for Drift Estimation in Stochastic Differential Equations
- Log in to post comments
This paper is concerned with the estimation of unknown drift functions of stochastic differential equations (SDEs) from observations of their sample paths. We propose to formulate this as a non-parametric Gaussian process regression problem and use an Itô-Taylor expansion for approximating the SDE. To address the computational complexity problem of Gaussian process regression, we cast the model in an equivalent state-space representation, such that (non-linear) Kalman filters and smoothers can be used.
- Categories:
19 Views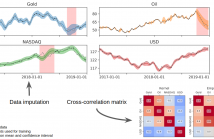
In Financial Signal Processing, multiple time series such as financial indicators, stock prices and exchange rates are strongly coupled due to their dependence on the latent state of the market and therefore they are required to be jointly analysed. We focus on learning the relationships among financial time series by modelling them through a multi-output Gaussian process (MOGP) with expressive covariance functions. Learning these market dependencies among financial series is crucial for the imputation and prediction of financial observations.
- Categories:
20 Views
- Read more about EXTENDED VARIATIONAL INFERENCE FOR PROPAGATING UNCERTAINTY IN CONVOLUTIONAL NEURAL NETWORKS
- Log in to post comments
Model confidence or uncertainty is critical in autonomous systems as they directly tie to the safety and trustworthiness of
the system. The quantification of uncertainty in the output decisions of deep neural networks (DNNs) is a challenging
problem. The Bayesian framework enables the estimation of the predictive uncertainty by introducing probability distributions
over the (unknown) network weights; however, the propagation of these high-dimensional distributions through
- Categories:
53 Views
- Read more about Minimax Active Learning via Minimal Model Capacity
- Log in to post comments
Active learning is a form of machine learning which combines supervised learning and feedback to minimize the training set size, subject to low generalization errors. Since direct optimization of the generalization error is difficult, many heuristics have been developed which lack a firm theoretical foundation. In this paper, a new information theoretic criterion is proposed based on a minimax log-loss regret formulation of the active learning problem. In the first part of this paper, a Redundancy Capacity theorem for active learning is derived along with an optimal learner.
- Categories:
101 Views
- Read more about Regularized state estimation and parameter learning via augmented Lagrangian Kalman smoother method
- Log in to post comments
In this article, we address the problem of estimating the state and learning of the parameters in a linear dynamic system with generalized $L_1$-regularization. Assuming a sparsity prior on the state, the joint state estimation and parameter learning problem is cast as an unconstrained optimization problem. However, when the dimensionality of state or parameters is large, memory requirements and computation of learning algorithms are generally prohibitive.
- Categories:
76 Views
- Read more about Sparse Bayesian Learning for Robust PCA
- Log in to post comments
SBL_RPCA.pdf
- Categories:
56 Views