- Read more about FastGAT: Simple and Efficient Graph Attention Neural Network with Global-aware Adaptive Computational Node Attention
- Log in to post comments
Graph attention neural network (GAT) stands as a fundamental model within graph neural networks, extensively employed across various applications. It assigns different weights to different nodes for feature aggregation by comparing the similarity of features between nodes. However, as the amount and density of graph data increases, GAT's computational demands rise steeply. In response, we present FastGAT, a simpler and more efficient graph attention neural network with global-aware adaptive computational node attention.
- Categories:
 20 Views
20 Views
- Read more about Quantum Privacy Aggregation of Teacher Ensembles (QPATE) for Privacy-preserving Quantum Machine Learning
- Log in to post comments
The utility of machine learning has rapidly expanded in the last two decades and presented an ethical challenge. Papernot et. al. developed a technique, known as Private Aggregation of Teacher Ensembles (PATE) to enable federated learning in which multiple \emph{distributed teachers} are trained on disjoint data sets. This study is the first to apply PATE to an ensemble of quantum neural networks (QNN) to pave a new way of ensuring privacy in quantum machine learning (QML).
- Categories:
34 Views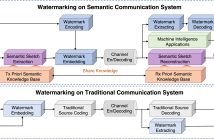
- Read more about SEMANTIC SECURITY: A DIGITAL WATERMARK METHOD FOR IMAGE SEMANTIC PRESERVATION
- Log in to post comments
This is a poster on a proposed watermarking method. In the research, we first chose position vector domain instead of traditional spatial or frequency domain. In addition, we successfully implemented watermarking on semantic communication system. Third, we modeled watermarking channel so that researchers could systematically research watermarking process.
For more information, please check out the publication at IEEE Xplore:
- Categories:
31 Views
- Read more about CROSS BRANCH FEATURE FUSION DECODER FOR CONSISTENCY REGULARIZATION-BASED SEMI-SUPERVISED CHANGE DETECTION
- Log in to post comments
Semi-supervised change detection (SSCD) utilizes partially labeled data and a large amount of unlabeled data to detect changes. However, the transformer-based SSCD network does not perform as well as the convolution-based SSCD network due to the lack of labeled data. To overcome this limitation, we introduce a new decoder called Cross Branch Feature Fusion (CBFF), which combines the strengths of both local convolutional branch and global transformer branch. The convolutional branch is easy to learn and can produce high-quality features with a small amount of labeled data.
- Categories:
21 Views
- Read more about SpectrumNet: Spectrum-based Trajectory Encode Neural Network for Pedestrian Trajectory Prediction
- Log in to post comments
Extracting motion pattern implied in the history trajectory is important for the pedestrian trajectory prediction task. The motion pattern determines how a pedestrian moves, including but not limited to reaction of interaction, tendency of speed and direction change. Although the motion pattern is a comprehensive concept and can’t be described concretely, it is clear that it contains both long-term and short-term factors. Inspired by this, we introduce SpectrumNet which enables more effective encoding of historical motion patterns for trajectory prediction.
- Categories:
22 Views
- Read more about Robust Self-Supervised Learning With Contrast Samples For Natural Language Understanding
- Log in to post comments
To improve the robustness of pre-trained language models (PLMs), previous studies have focused more on how to efficiently obtain adversarial samples with similar semantics, but less attention has been paid to the perturbed samples that change the gold label. Therefore, to fully perceive the effects of these different types of small perturbations on robustness, we propose a RObust Self-supervised leArning (ROSA) method, which incorporates different types of perturbed samples and the robustness improvements into a unified framework.
- Categories:
28 Views
- Read more about Feature Mixing-based Active Learning for Multi-label Text Classification
- Log in to post comments
Active learning (AL) aims to reduce labeling costs by selecting the most valuable samples to annotate from a set of unlabeled data. However, recognizing these samples is particularly challenging in multi-label text classification tasks due to the high dimensionality but sparseness of label spaces. Existing AL techniques either fail to sufficiently capture label correlations, resulting in label imbalance in the selected samples, or suffer significant computing costs when analyzing the informative potential of unlabeled samples across all labels.
- Categories:
26 Views
- Read more about A 3D VIRTUAL TRY-ON METHOD WITH GLOBAL-LOCAL ALIGNMENT AND DIFFUSION MODEL
- Log in to post comments
3D virtual try-on has recently received more attention due to its great practical and commercial value. However, there remains the problems that the garment cannot accurately correspond to a human body by geometric transformation and abnormal textures may be produced in the synthesis result. To address these issues, a 3D virtual try-on method with globallocal alignment and diffusion model is proposed. The globallocal alignment module is designed for more accurate garment warping, combined with the guidance of an “after-tryon” semantic map alignment.
poster.pdf
- Categories:
46 Views- Read more about NEURAL NETWORK-BASED SYMBOLIC REGRESSION FOR EMPIRICAL MODELING OF THE BEHAVIOR OF A PLANETARY GEARBOX
- Log in to post comments
Gearbox condition monitoring and quality surveillance are crucial techniques to ensure safe and cost-efficient machine operations. In condition monitoring, the interpretation of the different vibration spectrum elements is still an open question, many works show that some predefined vibration models are improper to explain the spectrum contents. In this paper, we investigate a method to identify the mixture model that describes a single-stage planetary gearbox vibration to properly interpret the vibration spectrum.
- Categories:
20 Views
- Read more about PROMPTING AUDIOS USING ACOUSTIC PROPERTIES FOR EMOTION REPRESENTATION
- Log in to post comments
Emotions lie on a continuum, but current models treat emotions
as a finite valued discrete variable. This representation does not
capture the diversity in the expression of emotion. To better rep-
resent emotions we propose the use of natural language descrip-
tions (or prompts). In this work, we address the challenge of au-
tomatically generating these prompts and training a model to better
learn emotion representations from audio and prompt pairs. We use
acoustic properties that are correlated to emotion like pitch, intensity,
- Categories:
29 Views