
ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The ICASSP 2020 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit website.

- Read more about Multi-level deep neural network adaptation for speaker verification using MMD and consistency regularization
- Log in to post comments
Adapting speaker verification (SV) systems to a new environ- ment is a very challenging task. Current adaptation methods in SV mainly focus on the backend, i.e, adaptation is carried out after the speaker embeddings have been created. In this paper, we present a DNN-based adaptation method using maximum mean discrepancy (MMD). Our method exploits two important aspects neglected by previous research.
- Categories:
 11 Views
11 Views
- Categories:
28 Views
- Read more about Information Maximized Variational Domain Adversarial Learning for Speaker Verification
- Log in to post comments
Domain mismatch is a common problem in speaker ver- ification. This paper proposes an information-maximized variational domain adversarial neural network (InfoVDANN) to reduce domain mismatch by incorporating an InfoVAE into domain adversarial training (DAT). DAT aims to pro- duce speaker discriminative and domain-invariant features. The InfoVAE has two roles. First, it performs variational regularization on the learned features so that they follow a Gaussian distribution, which is essential for the standard PLDA backend.
- Categories:
21 Views
- Read more about DENOISING OF EVENT-BASED SENSORS WITH SPATIAL-TEMPORAL CORRELATION
- Log in to post comments
- Categories:
66 Views
- Read more about A LIGHTWEIGHT MULTI-LABEL SEGMENTATION NETWORK FOR MOBILE IRIS BIOMETRICS
- Log in to post comments
- Categories:
27 Views
- Read more about Cross-domain Joint Dictionary Learning for ECG Reconstruction from PPG
- Log in to post comments
An emerging research direction considers the inverse problem of inferring electrocardiogram (ECG) from photoplethysmogram (PPG) to bring about the synergy between the easy measurability of PPG and the rich clinical knowledge of ECG to facilitate preventive healthcare. Previous reconstruction using a universal basis has limited accuracy due to the lack of rich representative power. This paper proposes a cross-domain joint dictionary learning (XDJDL) framework to maximize the expressive power for the two cross-domain signals.
- Categories:
242 Views
- Read more about Mask-dependent Phase Estimation for Monaural Speaker Separation
- Log in to post comments
Speaker Separation refers to isolating speech of interest in a multi-talker environment. Most methods apply real-valued Time-Frequency (T-F) masks to the mixture Short-Time Fourier Transform (STFT) to reconstruct the clean speech. Hence there is an unavoidable mismatch between the phase of the reconstruction and the original phase of the clean speech. In this paper, we propose a simple yet effective phase estimation network that predicts the phase of the clean speech based on a T-F mask predicted by a chimera++ network.
- Categories:
15 Views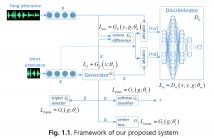
- Read more about ICASSP2020 TEXT-INDEPENDENT SPEAKER VERIFICATION WITH ADVERSARIAL LEARNING ON SHORT UTTERANCES
- Log in to post comments
A text-independent speaker verification system suffers severe performance degradation under short utterance condition. To address the problem, in this paper, we propose an adversarially learned embedding mapping model that directly maps a short embedding to an enhanced embedding with increased discriminability. In particular, a Wasserstein GAN with a bunch of loss criteria are investigated. These loss functions have distinct optimization objectives and some of them are less favoured for the speaker verification research area.
- Categories:
81 Views
- Read more about A Memory Augmented Architecture For Continuous Speaker Identification In Meetings
- Log in to post comments
We introduce and analyze a novel approach to the problem of speaker identification in multi-party recorded meetings. Given a speech segment and a set of available candidate profiles, a data-driven approach is proposed learning the distance relations between them, aiming at identifying the correct speaker label corresponding to that segment. A recurrent, memory-based architecture is employed, since this class of neural networks has been shown to yield improved performance in problems requiring relational reasoning.
- Categories:
38 Views
- Read more about ON THROUGHPUT OF MILLIMETER WAVE MIMO SYSTEMS WITH LOW RESOLUTION ADCS
- Log in to post comments
Use of low resolution analog to digital converters (ADCs) is an effective way to reduce the high power consumption of millimeter wave (mmWave) receivers. In this paper, a receiver with low resolution ADCs based on adaptive thresholds is considered in downlink mmWave communications in which the channel state information is not known a-priori and acquired through channel estimation. A performance comparison of low-complexity algorithms for power and ADC allocation among transmit and receive terminals, respectively, is provided.
- Categories:
26 Views