
ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The ICASSP 2020 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit website.

- Read more about Slides of my paper in ICASSP2020: Greedy Hybrid Rate Adaptation in Dynamic Wireless Communication environment
- Log in to post comments
- Categories:
 40 Views
40 Views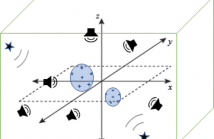
- Read more about Active noise control over multiple regions: performance analysis
- Log in to post comments
Active noise control (ANC) over space is a well-researched topic where multi-microphone, multi-loudspeaker systems are designed to minimize the noise over a spatial region of interest. In this paper, we perform an initial study on the more complex problem of simultaneous noise control over multiple target regions using a single ANC system. In particular, we investigate the maximum active noise control performance over the multiple target regions, given a particular setup of secondary loudspeakers.
- Categories:
36 Views
- Read more about Robust Hybrid Beamforming for Satellite-Terrestrial Integrated Networks
- 1 comment
- Log in to post comments
- Categories:
29 Views
- Read more about Speaker Diarization with Session-level Speaker Embedding Refinement using Graph Neural Networks
- Log in to post comments
Deep speaker embedding models have been commonly used as a building block for speaker diarization systems; however, the speaker embedding model is usually trained according to a global loss defined on the training data, which could be sub-optimal for distinguishing speakers locally in a specific meeting session. In this work we present the first use of graph neural networks (GNNs) for the speaker diarization problem, utilizing a GNN to refine speaker embeddings locally using the structural information between speech segments inside each session.
- Categories:
40 Views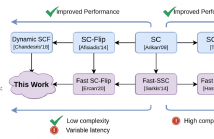
- Read more about SIMPLIFIED DYNAMIC SC-FLIP POLAR DECODING
- Log in to post comments
SC-Flip (SCF) decoding is a low-complexity polar code decoding algorithm alternative to SC-List (SCL) algorithm with small list sizes. To achieve the performance of the SCL algorithm with large list sizes, the Dynamic SC-Flip (DSCF) algorithm was proposed. However, DSCF involves logarithmic and exponential computations that are not suitable for practical hardware implementations. In this work, we propose a simple approximation that replaces the transcendental computations of DSCF decoding. Moreover, we show how to incorporate fast decoding techniques with the DSCF algorithm.
- Categories:
60 Views
We present an electrocardiogram (ECG) -based emotion recognition system using self-supervised learning. Our proposed architecture consists of two main networks, a signal transformation recognition network and an emotion recognition network. First, unlabelled data are used to successfully train the former network to detect specific pre-determined signal transformations in the self-supervised learning step.
- Categories:
58 Views
- Read more about An Analysis of Speech Enhancement and Recognition Losses in Limited Resources Multi-Talker Single Channel Audio-Visual ASR
- Log in to post comments
In this paper, we analyzed how audio-visual speech enhancement can help to perform the ASR task in a cocktail party scenario. Therefore we considered two simple end-to-end LSTM-based models that perform single-channel audiovisual speech enhancement and phone recognition respectively. Then, we studied how the two models interact, and how to train them jointly affects the final result.We analyzed different training strategies that reveal some interesting and unexpected behaviors.
- Categories:
54 Views
- Read more about A Streaming On-Device End-to-End Model Surpassing Server-Side Conventional Model Quality and Latency
- Log in to post comments
- Categories:
51 Views
- Read more about Evaluation of Sensor Self-Noise In Binaural Rendering of Spherical Microphone Array Signals
- Log in to post comments
Spherical microphone arrays are used to capture spatial sound fields, which can then be rendered via headphones. We use the Real-Time Spherical Array Renderer (ReTiSAR) to analyze and auralize the propagation of sensor self-noise through the processing pipeline. An instrumental evaluation confirms a strong global influence of different array and rendering parameters on the spectral balance and the overall level of the rendered noise. The character of the noise is direction independent in the case of spatially uniformly distributed noise.
- Categories:
13 Views
- Read more about 'MEDIA CLASSIFICATION WITH BAYESIAN OPTIMIZATION AND VAPNIK-CHERVONENKIS (VC) BOUNDS
- 1 comment
- Log in to post comments
The automatic classification of content is an essential requirement for multimedia applications. Present research for audio-based classifiers uses short- and long-term analysis of signals, with temporal and spectral features. In our prior study, we presented an approach to classify streaming and local content, in real-time and with low latency, using synthetically-derived metadata features based on fixed class-conditional distributions. The three-class conditional distribution parameters were set a priori based on public information.
- Categories:
17 Views