- Image/Video Storage, Retrieval
- Image/Video Processing
- Image/Video Coding
- Image Scanning, Display, and Printing
- Image Formation
- Read more about DIRECT MULTI-SCALE DUAL-STREAM NETWORK FOR PEDESTRIAN DETECTION
- Log in to post comments
- Categories:
 5 Views
5 Views
- Read more about SINGLE DEPTH IMAGE SUPER-RESOLUTION AND DENOISING BASED ON SPARSE GRAPHS VIA STRUCTURE TENSOR
- Log in to post comments
The existing single depth image super-resolution (SR)
methods suppose that the image to be interpolated is noise
free. However, the supposition is invalid in practice because
noise will be inevitably introduced in the depth image acquisition
process. In this paper, we address the problem of image
denoising and SR jointly based on designing sparse graphs
that are useful for describing the geometric structures of data
domains. In our method, we first cluster similar patches in a
noisy depth image and compute an average patch. Different
- Categories:
17 Views- Read more about CONVOLUTIONAL NEURAL NETWORKS FOR LICENSE PLATE DETECTION IN IMAGES
- Log in to post comments
License plate detection is a challenging task when dealing with open environments and images captured from a certain distance by lowcost cameras. In this paper, we propose an approach for detecting license plates based on a convolutional neural network which models a function that produces a score for each image sub-region, allowing us to estimate the locations of the detected license plates by combining the results obtained from sparse overlapping regions.
- Categories:
77 Views
- Read more about Investigating the Impact of High Frame Rates on Video Compression
- Log in to post comments
- Categories:
19 Views
- Read more about Comp-LOP: Complex Form of Local Orientation Plane for Object Tracking
- Log in to post comments
In this paper, we propose complex form of local orientation plane (Comp-LOP) for object tracking. Comp-LOP is a simple but effective descriptor, which is robust to occlusion for object tracking. It effectively considers spatiotemporal relationship between the target and its surrounding regions in a correlation filter framework by the complex form, which successfully deals with the heavy occlusion problem. Moreover, scale estimation is performed to treat target scale variations for improving tracking accuracy.
- Categories:
25 Views- Read more about 2563 sliding window filter based unknown object pose estimation
- Log in to post comments
- Categories:
28 Views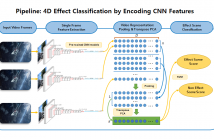
- Read more about 4D Effect Classification by Encoding CNN Features
- Log in to post comments
4D effects are physical effects simulated in sync with videos, movies, and games to augment the events occurring in a story or a virtual world. Types of 4D effects commonly used for the immersive media may include seat motion, vibration, flash, wind, water, scent, thunderstorm, snow, and fog. Currently, the recognition of physical effects from a video is mainly conducted by human experts. Although 4D effects are promising in giving immersive experience and entertainment, this manual production has been the main obstacle to faster and wider application of 4D effects.
- Categories:
42 Views- Read more about SAR Image Despeckling by Combination of Fractional-Order Total Variation and Nonlocal Low Rank Regularization
- Log in to post comments
This paper proposes a combinational regularization model for synthetic aperture radar (SAR) image despeckling. In contrast to most of the well-known regularization methods that only use one image prior property, the proposed combinational regularization model includes both fractional-order total variation (FrTV) regularization term and nonlocal low rank (NLR) regularization term.
- Categories:
19 Views- Read more about ByNet-SR: Image Super Resolution with a Bypass Connection Network
- Log in to post comments
- Categories:
17 Views- Read more about Inter-Camera Tracking Based On Fully Unsupervised Online Learning
- Log in to post comments
In this paper, we present a novel fully automatic approach to track the same human across multiple disjoint cameras. Our framework includes a two-phase feature extractor and an online-learning-based camera link model estimation. We introduce an effective and robust integration of appearance and context features. Couples are detected automatically, and the couple feature is also integrated with appearance features effectively. The proposed algorithm is scalable with the use of a fully unsupervised online learning framework.
poster_2.pdf
- Categories:
29 Views