
- Read more about MODE DOMAIN SPATIAL ACTIVE NOISE CONTROL USING SPARSE SIGNAL REPRESENTATION
- Log in to post comments
Active noise control (ANC) over a sizeable space requires a large number of reference and error microphones to satisfy the spatial Nyquist sampling criterion, which limits the feasibility of practical realization of such systems. This paper proposes a mode-domain feedforward ANC method to attenuate the noise field over a large space while reducing the number of microphones required.
- Categories:
 33 Views
33 Views
- Read more about MULTICHANNEL SPEECH SEPARATION WITH RECURRENT NEURAL NETWORKS FROM HIGH-ORDER AMBISONICS RECORDINGS
- Log in to post comments
We present a source separation system for high-order ambisonics (HOA) contents. We derive a multichannel spatial filter from a mask estimated by a long short-term memory (LSTM) recurrent neural network. We combine one channel of the mixture with the outputs of basic HOA beamformers as inputs to the LSTM, assuming that we know the directions of arrival of the directional sources. In our experiments, the speech of interest can be corrupted either by diffuse noise or by an equally loud competing speaker.
perotin.pdf
- Categories:
24 Views
- Read more about Spatial audio feature discovery with convolutional neural networks
- Log in to post comments
The advent of mixed reality consumer products brings about a pressing need to develop and improve spatial sound rendering techniques for a broad user base. Despite a large body of prior work, the precise nature and importance of various sound localization cues and how they should be personalized for an individual user to improve localization performance is still an open research problem. Here we propose training a convolutional neural network (CNN) to classify the elevation angle of spatially rendered sounds and employing Layerwise Relevance Propagation (LRP) on the trained CNN model.
- Categories:
40 Views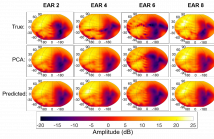
- Read more about Considerations regarding individualization of head-related transfer functions
- Log in to post comments
This paper provides some considerations regarding using individualized head-related transfer functions for rendering binaural spatial audio over headphones. It briefly considers the degree of benefit that individualization may provide. It then examines the degree of variation existing within the ear morphology across listeners within the Sydney-York Morphological and Recording of Ears (SYMARE) database using kernel principal component analysis and the large deformation diffeomorphic metric mapping framework.
- Categories:
36 Views
- Read more about AN IMMERSIVE 3D AUDIO HEADSET FOR VIRTUAL AND AUGMENTED REALITY
- Log in to post comments
- Categories:
37 Views
- Read more about ICASSP 2018 Tutorial T11 Natual and Augmented Listening for VR/AR/MR
- Log in to post comments
This tutorial aims to equip the participants with basic and advanced signal processing techniques that can be used in VR/AR applications to create a natural and augmented listening experience using headsets.
This tutorial is divided into 5 sections and cover following topics:
Introduction to spatial audio, fundamentals in natural listening, and emerging audio applications
- Categories:
387 Views
- Read more about A UNIFIED APPROACH TO GENERATING SOUND ZONES USING VARIABLE SPAN LINEAR FILTERS
- Log in to post comments
Sound zones are typically created using Acoustic Contrast Control (ACC), Pressure Matching (PM), or variations of the two. ACC maximizes the acoustic potential energy contrast between a listening zone and a quiet zone. Although the contrast is maximized, the phase is not controlled. To control both the amplitude and the phase, PM instead minimizes the difference between the reproduced sound field and the desired sound field in all zones.
- Categories:
97 Views
- Read more about ICASSP 2018 Tutorial T11 Natual and Augmented Listening for VR/AR/MR
- Log in to post comments
This tutorial aims to equip the participants with basic and advanced signal processing techniques that can be used in VR/AR applications to create a natural and augmented listening experience using headsets.
This tutorial is divided into 5 sections and cover following topics:
Introduction to spatial audio, fundamentals in natural listening, and emerging audio applications
- Categories:
201 Views
- Read more about Sound field reproduction with exterior cancellation using analytical weighting of harmonic coefficients
- Log in to post comments
A method for sound field reproduction with the suppression of exterior radiation is proposed, which makes it possible to synthesize a desired sound field in a reverberant environment without prior knowledge of the transfer functions of the multiple loudspeakers. The objective function used to achieve this is formulated as the weighted sum of the interior reproduction error and exterior radiation power. The optimal driving signals are derived by harmonic expansion of both the interior and exterior sound fields.
20180413.pdf
- Categories:
15 Views
- Read more about JOINT SOURCE AND SENSOR PLACEMENT FOR SOUND FIELD CONTROL BASED ON EMPIRICAL INTERPOLATION METHOD
- Log in to post comments
This study proposes a principled method to jointly determine the placement of acoustic sources (loudspeakers) and sensors (control points/microphones) in sound field control. The goal of this setup is to efficiently produce a sound field using multiple loudspeakers, approximately matching a target sound field over a region of interest.
icassp2018.pdf
- Categories:
27 Views