ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The 2019 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit website.

This paper presents an ultimate extension of nonnegative matrix factorization (NMF) for audio source separation based on full covariance modeling over all the time-frequency (TF) bins of the complex spectrogram of an observed mixture signal. Although NMF has been widely used for decomposing an observed power spectrogram in a TF-wise manner, it has a critical limitation that the phase values of interdependent TF bins cannot be dealt with.
- Categories:
 45 Views
45 Views
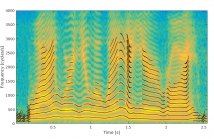
- Read more about Time-Frequency Networks for Audio Super-Resolution
- Log in to post comments
Audio super-resolution (a.k.a. bandwidth extension) is the challenging task of increasing the temporal resolution of audio signals. Recent deep networks approaches achieved promising results by modeling the task as a regression problem in either time or frequency domain. In this paper, we introduced Time-Frequency Network (TFNet), a deep network that utilizes supervision in both the time and frequency domain. We proposed a novel model architecture which allows the two domains to be jointly optimized.
- Categories:
343 Views
- Read more about Image Restoration with Deep Generative Models
- Log in to post comments
Many image restoration problems are ill-posed in nature, hence, beyond the input image, most existing methods rely on a carefully engineered image prior, which enforces some local image consistency in the recovered image. How tightly the prior assumptions are fulfilled has a big impact on the resulting task performance. To obtain more flexibility, in this work, we proposed to design the image prior in a data-driven manner. Instead of explicitly defining the prior, we learn it using deep generative models.
- Categories:
227 Views
- Read more about A UNIFIED APPROACH TO GENERATING SOUND ZONES USING VARIABLE SPAN LINEAR FILTERS
- Log in to post comments
Sound zones are typically created using Acoustic Contrast Control (ACC), Pressure Matching (PM), or variations of the two. ACC maximizes the acoustic potential energy contrast between a listening zone and a quiet zone. Although the contrast is maximized, the phase is not controlled. To control both the amplitude and the phase, PM instead minimizes the difference between the reproduced sound field and the desired sound field in all zones.
- Categories:
97 Views
- Read more about Deep Clustering with Gated Convolutional Networks
- Log in to post comments
- Categories:
87 Views
- Read more about ICASSP 2018 Tutorial T11 Natual and Augmented Listening for VR/AR/MR
- Log in to post comments
This tutorial aims to equip the participants with basic and advanced signal processing techniques that can be used in VR/AR applications to create a natural and augmented listening experience using headsets.
This tutorial is divided into 5 sections and cover following topics:
Introduction to spatial audio, fundamentals in natural listening, and emerging audio applications
- Categories:
202 Views
- Read more about AN IMPROVED INITIALIZATION FOR LOW-RANK MATRIX COMPLETION BASED ON RANK-1 UPDATES
- Log in to post comments
Given a data matrix with partially observed entries, the low-rank matrix completion problem is one of finding a matrix with the lowest rank that perfectly fits the given observations. While there exist convex relaxations for the low-rank completion problem, the underlying problem is inherently non-convex, and most algorithms (alternating projection, Riemannian optimization, etc.) heavily depend on the initialization. This paper proposes an improved initialization that relies on successive rank-1 updates.
- Categories:
35 Views
- Read more about CROSS-LINGUAL AND MULTILINGUAL SPEECH EMOTION RECOGNITION ON ENGLISH AND FRENCH
- Log in to post comments
poster_final.pdf
- Categories:
36 Views
- Read more about EFFICIENT INTEGRATION OF FIXED BEAMFORMERS AND SPEECH SEPARATION NETWORKS FOR MULTICHANNEL FAR-FIELD SPEECH SEPARATION
- Log in to post comments
- Categories:
12 Views