
ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The 2019 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit website.

- Read more about A compressive sensing-based active user and symbol detection for massive machine type communications
- Log in to post comments
- Categories:
 20 Views
20 Views
- Read more about ICASSP 2018 Tutorial T11 Natual and Augmented Listening for VR/AR/MR
- Log in to post comments
This tutorial aims to equip the participants with basic and advanced signal processing techniques that can be used in VR/AR applications to create a natural and augmented listening experience using headsets.
This tutorial is divided into 5 sections and cover following topics:
Introduction to spatial audio, fundamentals in natural listening, and emerging audio applications
- Categories:
391 Views
- Categories:
8 Views
- Read more about Restoration of ultrasound images using spatially-variant kernel deconvolution
- Log in to post comments
Most of the existing ultrasound image restoration methods consider a spatially-invariant point-spread function (PSF) model and circulant boundary conditions. While computationally efficient, this model is not realistic and severely limits the quality of reconstructed images. In this work, we address ultrasound image restoration under the hypothesis of vertical variation of the PSF. To regularize the solution, we use the classical elastic net constraint.
- Categories:
53 Views
- Read more about NATURAL TTS SYNTHESIS BY CONDITIONING WAVENET ON MEL SPECTROGRAM PREDICTIONS
- Log in to post comments
- Categories:
80 Views
- Read more about SVSGAN: SINGING VOICE SEPARATION VIA GENERATIVE ADVERSARIAL NETWORK
- Log in to post comments
- Categories:
35 Views
- Read more about Attention-based End-to-end Speech Recognition on Voice Search
- Log in to post comments
SP-L1.4.pdf
- Categories:
16 Views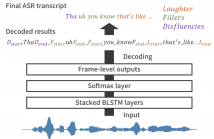
- Read more about AN END-TO-END APPROACH TO JOINT SOCIAL SIGNAL DETECTION AND AUTOMATIC SPEECH RECOGNITION
- Log in to post comments
Social signals such as laughter and fillers are often observed in natural conversation, and they play various roles in human-to-human communication. Detecting these events is useful for transcription systems to generate rich transcription and for dialogue systems to behave as we do such as synchronized laughing or attentive listening. We have studied an end-to-end approach to directly detect social signals from speech by using connectionist temporal classification (CTC), which is one of the end-to-end sequence labelling models.
- Categories:
14 Views
- Read more about TEXT-TO-SPEECH SYNTHESIS USING STFT SPECTRA BASED ON LOW-/MULTI-RESOLUTION GENERATIVE ADVERSARIAL NETWORKS
- Log in to post comments
- Categories:
32 Views
- Read more about NON-PARALLEL VOICE CONVERSION USING VARIATIONAL AUTOENCODERS CONDITIONED BY PHONETIC POSTERIORGRAMS AND D-VECTORS
- Log in to post comments
- Categories:
28 Views