
ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The 2019 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit website.

- Categories:
 16 Views
16 Views
- Read more about A Comparison of Five Multiple Instance Learning Pooling Functions for Sound Event Detection with Weak Labeling
- Log in to post comments
Sound event detection (SED) entails two subtasks: recognizing what types of sound events are present in an audio stream (audio tagging), and pinpointing their onset and offset times (localization). In the popular multiple instance learning (MIL) framework for SED with weak labeling, an important component is the pooling function. This paper compares five types of pooling functions both theoretically and experimentally, with special focus on their performance of localization.
- Categories:
13 Views
- Read more about CNN Based Two-Stage Multi-Resolution End-to-End Model for Singing Melody Extraction
- Log in to post comments
Inspired by human hearing perception, we propose a twostage multi-resolution end-to-end model for singing melody extraction in this paper. The convolutional neural network (CNN) is the core of the proposed model to generate multiresolution representations. The 1-D and 2-D multi-resolution analysis on waveform and spectrogram-like graph are successively carried out by using 1-D and 2-D CNN kernels of different lengths and sizes.
- Categories:
33 Views
- Read more about Retrieving Speech Samples with Similar Emotional Content Using a Triplet Loss Function
- Log in to post comments
The ability to identify speech with similar emotional content is valuable to many applications, including speech retrieval, surveillance, and emotional speech synthesis. While current formulations in speech emotion recognition based on classification or regression are not appropriate for this task, solutions based on preference learning offer appealing approaches for this task. This paper aims to find speech samples that are emotionally similar to an anchor speech sample provided as a query. This novel formulation opens interesting research questions.
- Categories:
26 Views
- Read more about REINFORCEMENT LEARNING BASED SPEECH ENHANCEMENT FOR ROBUST SPEECH RECOGNITION
- Log in to post comments
- Categories:
69 Views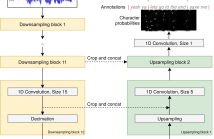
- Read more about End-to-End Lyrics Alignment Using An Audio-to-Character Recognition Model
- Log in to post comments
Time-aligned lyrics can enrich the music listening experience by enabling karaoke, text-based song retrieval and intra-song navigation, and other applications. Compared to text-to-speech alignment, lyrics alignment remains highly challenging, despite many attempts to combine numerous sub-modules including vocal separation and detection in an effort to break down the problem. Furthermore, training required fine-grained annotations to be available in some form.
- Categories:
220 Views
- Read more about Face Landmark-based Speaker-Independent Audio-Visual Speech Enhancement in Multi-Talker Environments
- Log in to post comments
In this paper, we address the problem of enhancing the speech of a speaker of interest in a cocktail party scenario when visual information of the speaker of interest is available.Contrary to most previous studies, we do not learn visual features on the typically small audio-visual datasets, but use an already available face landmark detector (trained on a separate image dataset).The landmarks are used by LSTM-based models to generate time-frequency masks which are applied to the acoustic mixed-speech spectrogram.
- Categories:
20 Views
- Read more about Modality attention for end-to-end audio-visual speech recognition
- Log in to post comments
Audio-visual speech recognition (AVSR) system is thought to be one of the most promising solutions for robust speech recognition, especially in noisy environment. In this paper, we propose a novel multimodal attention based method for audio-visual speech recognition which could automatically learn the fused representation from both modalities based on their importance. Our method is realized using state-of-the-art sequence-to-sequence (Seq2seq) architectures.
- Categories:
30 Views
- Read more about Image reconstruction by orthogonal moments derived by the parity of polynomial
- Log in to post comments
Moments are a kind of classical feature descriptors for image analysis. Orthogonal moments, due to their computation
efficiency and numerical stability, have been widely developed.We propose a set of orthogonal polynomials which are
derived from the parity of Hermite polynomials. The new orthogonal polynomials are composed of either odd orders
or even ones of Hermite polynomials. They, however, are orthogonal in different domains. The corresponding orthogonal
- Categories:
23 Views