- Transducers
- Spatial and Multichannel Audio
- Source Separation and Signal Enhancement
- Room Acoustics and Acoustic System Modeling
- Network Audio
- Audio for Multimedia
- Audio Processing Systems
- Audio Coding
- Audio Analysis and Synthesis
- Active Noise Control
- Auditory Modeling and Hearing Aids
- Bioacoustics and Medical Acoustics
- Music Signal Processing
- Loudspeaker and Microphone Array Signal Processing
- Echo Cancellation
- Content-Based Audio Processing
- Read more about Human and Machine Speaker Recognition on Short Trivial Events
- Log in to post comments
In this paper, we collect a trivial event speech database that involves 75 speakers and 6 types of events, and report preliminary speaker recognition results on this database, by both human listeners and machines. Particularly, the deep feature learning technique recently proposed by our group is utilized to analyze and recognize the trivial events, leading to acceptable equal error rates (EERs) ranging from 5% to 15% despite the extremely short durations (0.2-0.5 seconds) of these events. Comparing different types of events, ‘hmm’ seems more speaker discriminative.
trivial.pdf
- Categories:
 12 Views
12 Views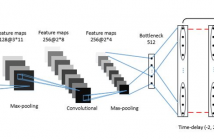
- Read more about Human and Machine Speaker Recognition on Short Trivial Events
- Log in to post comments
In this paper, we collect a trivial event speech database that involves 75 speakers and 6 types of events, and report preliminary speaker recognition results on this database, by both human listeners and machines. Particularly, the deep feature learning technique recently proposed by our group is utilized to analyze and recognize the trivial events, leading to acceptable equal error rates (EERs) ranging from 5% to 15% despite the extremely short durations (0.2-0.5 seconds) of these events. Comparing different types of events, ‘hmm’ seems more speaker discriminative.
trivial.pdf
- Categories:
19 Views
- Read more about Passive online geometry calibration of acoustic sensor networks
- Log in to post comments
As we are surrounded by an increased number of mobile devices equipped with wireless links and multiple microphones, e.g., smartphones, tablets, laptops and hearing aids, using them collaboratively for acoustic processing is a promising platform for emerging applications.
- Categories:
20 Views
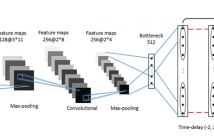
- Read more about DEEP CNN BASED FEATURE EXTRACTOR FOR TEXT-PROMPTED SPEAKER RECOGNITION
- Log in to post comments
Deep learning is still not a very common tool in speaker verification field. We study deep convolutional neural network performance in the text-prompted speaker verification task. The prompted passphrase is segmented into word states — i.e. digits — to test each digit utterance separately. We train a single high-level feature extractor for all states and use cosine similarity metric for scoring. The key feature of our network is the Max-Feature-Map activation function, which acts as an embedded feature selector.
- Categories:
15 Views
- Read more about Being low-rank in the time-frequency plane
- Log in to post comments
When using optimization methods with matrix variables in signal processing and machine learning, it is customary to assume some low-rank prior on the targeted solution. Nonnegative matrix factorization of spectrograms is a case in point in audio signal processing. However, this low-rank prior is not straightforwardly related to complex matrices obtained from a short-time Fourier -- or discrete Gabor -- transform (STFT), which is generally defined from and studied based on a modulation operator and a translation operator applied to a so-called window.
- Categories:
22 Views
- Read more about EADNET: EFFICIENT ARCHITECTURE FOR DECOMPOSED CONVOLUTIONAL NEURAL NETWORKS
- Log in to post comments
- Categories:
13 Views
- Read more about High-speed light field image formation analysis using wavefield modeling with flexible sampling
- Log in to post comments
In order to understand the image formation inside plenoptic systems, a wave-optic-based model is proposed in this paper that uses the Fresnel diffraction equation to propagate the whole object field into the plenoptic systems. The proposed model is much flexible at sampling on propagation planes by utilizing the method of multiple partial propagations. In order to verify the effectiveness of the proposed model, numerical simulations are conducted by comparing with existing wave optic model under different optical configurations of plenoptic cameras.
- Categories:
7 Views
- Read more about High-speed light field image formation analysis using wavefield modeling with flexible sampling
- Log in to post comments
In order to understand the image formation inside plenoptic systems, a wave-optic-based model is proposed in this paper that uses the Fresnel diffraction equation to propagate the whole object field into the plenoptic systems. The proposed model is much flexible at sampling on propagation planes by utilizing the method of multiple partial propagations. In order to verify the effectiveness of the proposed model, numerical simulations are conducted by comparing with existing wave optic model under different optical configurations of plenoptic cameras.
- Categories:
9 Views
- Categories:
8 Views
- Read more about REDUCING MODEL COMPLEXITY FOR DNN BASED LARGE-SCALE AUDIO CLASSIFICATION
- Log in to post comments
- Categories:
17 Views