- Transducers
- Spatial and Multichannel Audio
- Source Separation and Signal Enhancement
- Room Acoustics and Acoustic System Modeling
- Network Audio
- Audio for Multimedia
- Audio Processing Systems
- Audio Coding
- Audio Analysis and Synthesis
- Active Noise Control
- Auditory Modeling and Hearing Aids
- Bioacoustics and Medical Acoustics
- Music Signal Processing
- Loudspeaker and Microphone Array Signal Processing
- Echo Cancellation
- Content-Based Audio Processing

- Read more about Memory-Less Gain Quantization in the EVS Codec
- Log in to post comments
The recent standard on Enhanced Voiced Services (EVS) contains two memory-less gain coding mechanisms achieving better performance than the prediction-based techniques used in 3GPP AMR-WB and ITU-T G.729 codecs. The EVS gain encoder uses joint vector quantization without the need of information from previous frames. Inter-frame prediction is replaced by alternative schemes based on sub-frame prediction or estimated average target signal energy. This eliminates the propagation of error inside the adaptive codebook.
- Categories:
 9 Views
9 Views
- Read more about Time-Shifting Based Primary-Ambient Extraction for Spatial Audio Reproduction
- Log in to post comments
One of the key issues in spatial audio analysis and reproduction is to decompose a signal into primary and ambient components based on their directional and diffuse spatial features, respectively. Existing approaches employed in primary-ambient extraction (PAE), such as principal component analysis (PCA), are mainly based on a basic stereo signal model. The performance of these PAE approaches has not been well studied for the input signals that do not satisfy all the assumptions of the stereo signal model.
- Categories:
11 Views
- Read more about Multi-shift principal component analysis based primary component extraction for spatial audio reproduction (poster)
- Log in to post comments
In spatial audio analysis-synthesis, one of the key issues is to decompose a signal into primary and ambient components based on their spatial features. Principal component analysis (PCA) has been widely employed in primary component extraction, and shifted PCA (SPCA) is employed to enhance the primary extraction for input signals involving the inter-channel time difference. However, SPCA generally requires the primary components to come from one direction and cannot produce good results in the case of multiple directions.
- Categories:
12 Views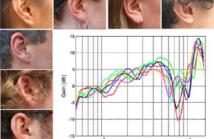
- Read more about On the Preprocessing and Postprocessing of HRTF individualization based on sparse representation of anthropometric features (poster)
- Log in to post comments
Individualization of head-related transfer functions (HRTFs) can be realized using the person’s anthropometry with a pre-trained model. This model usually establishes a direct linear or non-linear mapping from anthropometry to HRTFs in the training database. Due to the complex relation between anthropometry and HRTFs, the accuracy of this model depends heavily on the correct selection of the anthropometric features.
- Categories:
183 Views
- Read more about 3D Sound Effect Analysis, Synthesis and Application Design----A Primary-Ambient Extraction Approach (slides)
- Log in to post comments
In spatial audio analysis-synthesis, one of the key issues is to decompose a signal into primary and ambient components based on their spatial features. Stereo audio signals are often modeled as a linear mixture of primary and ambient components. Existing approaches like principal component analysis (PCA) and least squares (LS) have been widely employed to extract primary and ambient components from stereo signals. However, the performance and comparisons of these approaches in primary-ambient extraction (PAE) have not been well studied.
- Categories:
18 Views- Read more about 3D Sound Effect Analysis, Synthesis and Application Design----A Primary-Ambient Extraction Approach
- Log in to post comments
In spatial audio analysis-synthesis, one of the key issues is to decompose a signal into primary and ambient components based on their spatial features. Stereo audio signals are often modeled as a linear mixture of primary and ambient components. Existing approaches like principal component analysis (PCA) and least squares (LS) have been widely employed to extract primary and ambient components from stereo signals. However, the performance and comparisons of these approaches in primary-ambient extraction (PAE) have not been well studied.
- Categories:
28 Views
- Read more about Primary-Ambient Extraction Using Ambient Spectrum Estimation for Immersive Spatial Audio Reproduction
- Log in to post comments
The diversity of today’s playback systems requires a flexible, efficient, and immersive reproduction of sound scenes in digital media. Spatial audio reproduction based on primary-ambient extraction (PAE) fulfills this objective, where accurate extraction of primary and ambient components from sound mixtures in channel-based audio is crucial. Severe extraction error was found in existing PAE approaches when dealing with sound mixtures that contain a relatively strong ambient component, a commonly encountered case in the sound scenes of digital media.
- Categories:
21 Views
- Read more about Study on the use of error term in parallel-form narrowband feedback active noise control systems (slides)
- Log in to post comments
Parallel-form narrowband feedback active noise control (FBANC) system has been shown to perform better than conventional internal model control (IMC) based FBANC system in cancelling multi-tonal noise. A previous paper illustrated a novel approach in estimating the frequencies of the multi-tone noise, and using an internal tonal generator cum frequency grouping unit to increase its frequency separation in each channel of the parallel-form FBANC system based on a full-band error.
- Categories:
9 Views
- Read more about Study on the use of error term in parallel-form narrowband feedback active noise control systems
- Log in to post comments
Parallel-form narrowband feedback active noise control (FBANC) system has been shown to perform better than conventional internal model control (IMC) based FBANC system in cancelling multi-tonal noise. A previous paper illustrated a novel approach in estimating the frequencies of the multi-tone noise, and using an internal tonal generator cum frequency grouping unit to increase its frequency separation in each channel of the parallel-form FBANC system based on a full-band error.
- Categories:
24 Views
- Read more about On the Preprocessing and Postprocessing of HRTF individualization based on sparse representation of anthropometric features (slides)
- Log in to post comments
Individualization of head-related transfer functions (HRTFs) can be realized using the person’s anthropometry with a pre-trained model. This model usually establishes a direct linear or non-linear mapping from anthropometry to HRTFs in the training database. Due to the complex relation between anthropometry and HRTFs, the accuracy of this model depends heavily on the correct selection of the anthropometric features.
- Categories:
9 Views