- Read more about GlobalSIP 2018 Keynote: Tensors and Probability: An Intriguing Union (N. Sidiropoulos, N. Kargas, X. Fu)
- Log in to post comments
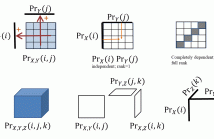
We reveal an interesting link between tensors and multivariate statistics. The rank of a multivariate probability tensor can be interpreted as a nonlinear measure of statistical dependence of the associated random variables. Rank equals one when the random variables are independent, and complete statistical dependence corresponds to full rank; but we show that rank as low as two can already model strong statistical dependence.
- Categories:
 114 Views
114 Views
- Read more about Large-Scale Algorithm Design for Parallel FFT-based Simulations on GPUs
- Log in to post comments
- Categories:
18 Views
- Categories:
16 Views
- Categories:
61 Views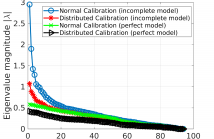
- Read more about Performance analysis of distributed radio interferometric calibration
- Log in to post comments
Distributed calibration based on consensus optimization is a computationally efficient method to calibrate large radio interferometers such as LOFAR and SKA. Calibrating along multiple directions in the sky and removing the bright foreground signal is a crucial step in many science cases in radio interferometry. The residual data contain weak signals of huge scientific interest and of particular concern is the effect of incomplete sky models used in calibration on the residual. In order to study this, we consider the mapping between the input uncalibrated data and the output residual data.
lofar75.pdf
lofar75.pdf
- Categories:
7 Views
- Read more about Multi-scale algorithms for optimal transport
- Log in to post comments
Optimal transport is a geometrically intuitive and robust way to quantify differences between probability measures.
It is becoming increasingly popular as numerical tool in image processing, computer vision and machine learning.
A key challenge is its efficient computation, in particular on large problems. Various algorithms exist, tailored to different special cases.
Multi-scale methods can be applied to classical discrete algorithms, as well as entropy regularization techniques. They provide a good compromise between efficiency and flexibility.
- Categories:
24 Views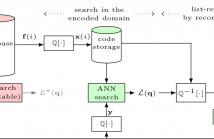
- Read more about Vector compression for similarity search using Multi-layer Sparse Ternary Codes
- Log in to post comments
It was shown recently that Sparse Ternary Codes (STC) posses superior ``coding gain'' compared to the classical binary hashing framework and can successfully be used for large-scale search applications. This work extends the STC for compression and proposes a rate-distortion efficient design. We first study a single-layer setup where we show that binary encoding intrinsically suffers from poor compression quality while STC, thanks to the flexibility in design, can have near-optimal rate allocation. We further show that single-layer codes should be limited to very low rates.
- Categories:
15 Views
In many settings, we can accurately model high-dimensional data as lying in a union of subspaces. Subspace clustering is the process of inferring the subspaces and determining which point belongs to each subspace. In this paper we study a ro- bust variant of sparse subspace clustering (SSC). While SSC is well-understood when there is little or no noise, less is known about SSC under significant noise or missing en- tries. We establish clustering guarantees in the presence of corrupted or missing entries.
- Categories:
154 Views
- Read more about SUBSAMPLING LEAST SQUARES AND ELEMENTAL ESTIMATION
- Log in to post comments
poster2018.pdf
- Categories:
12 Views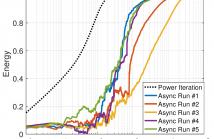
- Read more about THE ASYNCHRONOUS POWER ITERATION: A GRAPH SIGNAL PERSPECTIVE
- Log in to post comments
- Categories:
68 Views