
- Read more about INVESTIGATION OF ROBUSTNESS OF HUBERT FEATURES FROM DIFFERENT LAYERS TO DOMAIN, ACCENT AND LANGUAGE VARIATIONS
- Log in to post comments
In this paper, we investigate the use of pre-trained HuBERT model to build downstream Automatic Speech Recognition (ASR) models using data that have differences in domain, accent and even language. We use the standard ESPnet recipe with HuBERT as pretrained models whose output is fed as input features to a downstream Conformer model built from target domain data. We compare the performance of HuBERT pre-trained features with the baseline Conformer model built with Mel-filterbank features.
- Categories:
 67 Views
67 Views
- Read more about ADA-VAD: UNPAIRED ADVERSARIAL DOMAIN ADAPTATION FOR NOISE-ROBUST VOICE ACTIVITY DETECTION
- Log in to post comments
- Categories:
9 Views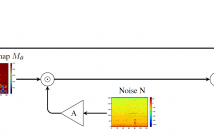
- Read more about ImportantAug: A Data Augmentation Agent For Speech
- Log in to post comments
We introduce ImportantAug, a technique to augment training data
for speech classification and recognition models by adding noise
to unimportant regions of the speech and not to important regions.
Importance is predicted for each utterance by a data augmentation
agent that is trained to maximize the amount of noise it adds while
minimizing its impact on recognition performance. The effectiveness
of our method is illustrated on version two of the Google Speech
Commands (GSC) dataset. On the standard GSC test set, it achieves
- Categories:
23 Views
The issue of fairness arises when the automatic speech recognition (ASR) systems do not perform equally well for all subgroups of the population. In any fairness measurement studies for ASR, the open questions of how to control the confounding factors, how to handle unobserved heterogeneity across speakers, and how to trace the source of any word error rate (WER) gap among different subgroups are especially important - if not appropriately accounted for, incorrect conclusions will be drawn.
- Categories:
16 Views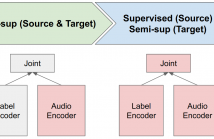
- Read more about Large-scale ASR Domain Adaptation using Self- and Semi-supervised Learning
- Log in to post comments
Self- and semi-supervised learning methods have been actively investigated to reduce labeled training data or enhance the model performance. However, the approach mostly focus on in-domain performance for public datasets. In this study, we utilize the combination of self- and semi-supervised learning methods to solve unseen domain adaptation problem in a large-scale production setting for online ASR model.
- Categories:
33 Views
- Read more about Privacy attacks for automatic speech recognition acoustic models in a federated learning framework
- Log in to post comments
This paper investigates methods to effectively retrieve speaker information from the personalized speaker adapted neural network acoustic models (AMs) in automatic speech recognition (ASR). This problem is especially important in the context of federated learning of ASR acoustic models where a global model is learnt on the server based on the updates received from multiple clients. We propose an approach to analyze information in neural network AMs based on a neural network footprint on the so-called Indicator dataset.
- Categories:
31 Views
- Read more about [ICASSP 2022] NOT ALL FEATURES ARE EQUAL: SELECTION OF ROBUST FEATURES FOR SPEECH EMOTION RECOGNITION IN NOISY ENVIRONMENTS
- Log in to post comments
Speech emotion recognition (SER) system deployed in real-world applications often encounters noisy speech. While most noise compensation techniques consider all acoustic features to have equal impact on the SER model, some acoustic features may be more sensitive to noisy conditions. This paper investigates the noise robustness of each feature in the acoustic feature set. We focus on low-level descriptors (LLDs) commonly used in SER systems. We firstly train SER models with clean speech by only using a single LLD.
- Categories:
25 Views
- Read more about WAV2VEC-SWITCH: CONTRASTIVE LEARNING FROM ORIGINAL-NOISY SPEECH PAIRS FOR ROBUST SPEECH RECOGNITION
- Log in to post comments
The goal of self-supervised learning (SSL) for automatic speech recognition (ASR) is to learn good speech representations from a large amount of unlabeled speech for the downstream ASR task. However, most SSL frameworks do not consider noise robustness which is crucial for real-world applications. In this paper we propose wav2vec-Switch, a method to encode noise robustness into contextualized representations of speech via contrastive learning. Specifically, we feed original-noisy speech pairs simultaneously into the wav2vec 2.0 network.
- Categories:
34 Views
Automatic speech recognition (ASR) systems are highly sensitive to train-test domain mismatch. However, because transcription is often prohibitively expensive, it is important to be able to make use of available transcribed out-of-domain data. We address the problem of domain adaptation with semi-supervised training (SST). Contrary to work in in-domain SST, we find significant performance improvement even with just one hour of target-domain data—though, the selection of the data is critical.
- Categories:
22 Views
- Read more about CASS-NAT: CTC Alignment-Based Single Step Non-Autoregressive Transformer for Speech Recognition
- Log in to post comments
We propose a CTC alignment-based single step non-autoregressive transformer (CASS-NAT) for speech recognition. Specifically, the CTC alignment contains the information of (a) the number of tokens for decoder input, and (b) the time span of acoustics for each token. The information are used to extract acoustic representation for each token in parallel, referred to as token-level acoustic embedding which substitutes the word embedding in autoregressive transformer (AT) to achieve parallel generation in decoder.
- Categories:
37 Views