
- Read more about TRIBYOL: TRIPLET BYOL FOR SELF-SUPERVISED REPRESENTATION LEARNING
- Log in to post comments
1917-1.pdf
- Categories:
 166 Views
166 Views
- Read more about 4D Convolutional Neural Networks for Multi Spectral and Multi Temporal Remote Sensing Data Classification
- Log in to post comments
Multi-temporal remotely sensed observations acquired by multi-spectral sensors contain a wealth of information related to the Earth’s state. Deep learning methods have demonstrated a great potential in analyzing such observations. Traditional 2D and 3D approaches are unable to effectively extract valuable information encoded across all available dimensions.
- Categories:
31 Views
- Read more about Mixture Model Auto-Encoders: Deep Clustering through Dictionary Learning
- Log in to post comments
mixmate.pdf
- Categories:
21 Views
- Read more about Neural Collapse in Deep Homogeneous Classifiers and the Role of Weight Decay
- Log in to post comments
Neural Collapse is a phenomenon recently discovered in deep classifiers where the last layer activations collapse onto their class means, while the means and last layer weights take on the structure of dual equiangular tight frames. In this paper we present results showing the role of weight decay in the emergence of Neural Collapse in deep homogeneous networks. We show that certain near-interpolating minima of deep networks satisfy the Neural Collapse condition, and this can be derived from the gradient flow on the regularized square loss.
- Categories:
35 Views
- Read more about Exploring Heterogeneous Characteristics of Layers in ASR Models for More Efficient Training
- Log in to post comments
Transformer-based architectures have been the subject of research aimed at understanding their overparameterization and the non-uniform importance of their layers. Applying these approaches to Automatic Speech Recognition, we demonstrate that the state-of-the-art Conformer models generally have multiple ambient layers. We study the stability of these layers across runs and model sizes, propose that group normalization may be used without disrupting their formation, and examine their correlation with model weight updates in each layer.
- Categories:
18 Views
- Read more about Exploring Heterogeneous Characteristics of Layers in ASR Models for More Efficient Training
- Log in to post comments
Transformer-based architectures have been the subject of research aimed at understanding their overparameterization and the non-uniform importance of their layers. Applying these approaches to Automatic Speech Recognition, we demonstrate that the state-of-the-art Conformer models generally have multiple ambient layers. We study the stability of these layers across runs and model sizes, propose that group normalization may be used without disrupting their formation, and examine their correlation with model weight updates in each layer.
- Categories:
15 Views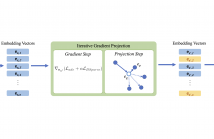
- Read more about BLOCK-SPARSE ADVERSARIAL ATTACK TO FOOL TRANSFORMER-BASED TEXT CLASSIFIERS
- Log in to post comments
Recently, it has been shown that, in spite of the significant performance of deep neural networks in different fields, those are vulnerable to adversarial examples. In this paper, we propose a gradient-based adversarial attack against transformer-based text classifiers. The adversarial perturbation in our method is imposed to be block-sparse so that the resultant adversarial example differs from the original sentence in only a few words. Due to the discrete nature of textual data, we perform gradient projection to find the minimizer of our proposed optimization problem.
- Categories:
42 Views
- Read more about SparseBFA: Attacking Sparse Deep Neural Networks with the Worst-Case Bit Flips on Coordinates
- Log in to post comments
poster.pdf
- Categories:
15 Views
- Read more about Towards Robust Visual Transformer Networks via K-Sparse Attention
- Log in to post comments
Transformer networks, originally developed in the community of machine translation to eliminate sequential nature of recurrent neural networks, have shown impressive results in other natural language processing and machine vision tasks. Self-attention is the core module behind visual transformers which globally mixes the image information. This module drastically reduces the intrinsic inductive bias imposed by CNNs, such as locality, while encountering insufficient robustness against some adversarial attacks.
- Categories:
35 Views