
- Read more about SAPT - ICIP2024 supplementary material
- Log in to post comments
Spatiality-Aware Prompt Tuning for Few-shot Small Object Detection - supplementary material for ICIP 2024
- Categories:
 39 Views
39 Views
- Read more about Supplementary Material for ``WrappingNet: Mesh Autoencoder via Deep Sphere Deformation''
- Log in to post comments
There have been recent efforts to learn more meaningful representations via fixed length codewords from mesh data, since a mesh serves as a complete model of underlying 3D shape compared to a point cloud. However, the mesh connectivity presents new difficulties when constructing a deep learning pipeline for meshes. Previous mesh unsupervised learning approaches typically assume category-specific templates, e.g., human face/body templates.
- Categories:
39 Views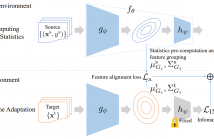
- Read more about COVARIANCE-AWARE FEATURE ALIGNMENT WITH PRE-COMPUTED SOURCE STATISTICS FOR TEST-TIME ADAPTATION TO MULTIPLE IMAGE CORRUPTIONS
- Log in to post comments
Real-world image recognition systems often face corrupted input images, which cause distribution shifts and degrade the performance of models. These systems often use a single prediction model in a central server and process images sent from various environments, such as cameras distributed in cities or cars. Such single models face images corrupted in heterogeneous ways in test time. Thus, they require to instantly adapt to the multiple corruptions during testing rather than being re-trained at a high cost.
- Categories:
139 Views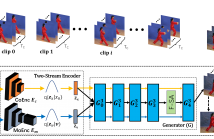
- Read more about ENABLING THE ENCODER-EMPOWERED GAN-BASED VIDEO GENERATORS FOR LONG VIDEO GENERATION
- Log in to post comments
We propose Recall Encoder-empowered GAN3 (REncGAN3), employing the recall mechanism to enable a standard short video (16-frame) generation model EncGAN3 for generating long videos of hundreds of frames.
The recall mechanism utilizes simple changes that enable the generation of connectable short video clips for merging into long sequences, maintaining long-duration consistency.
- Categories:
47 Views
- Read more about A Gradient Boosting Approach for Training Convolutional and Deep Neural Networks
- Log in to post comments
- Categories:
34 Views
- Read more about Interpreting Intermediate Convolutional Layers of Generative CNNs Trained on Waveforms
- Log in to post comments
This paper presents a technique to interpret and visualize intermediate layers in generative CNNs trained on raw speech data in an unsupervised manner. We argue that averaging over feature maps after ReLU activation in each transpose convolutional layer yields interpretable time-series data. This technique allows for acoustic analysis of intermediate layers that parallels the acoustic analysis of human speech data: we can extract F0, intensity, duration, formants, and other acoustic properties from intermediate layers in order to test where and how CNNs encode various types of information.
- Categories:
49 Views
- Read more about Learning Gradients of Convex Functions with Monotone Gradient Networks
- Log in to post comments
While much effort has been devoted to deriving and analyzing effective convex formulations of signal processing problems, the gradients of convex functions also have critical applications ranging from gradient-based optimization to optimal transport. Recent works have explored data-driven methods for learning convex objective functions, but learning their monotone gradients is seldom studied. In this work, we propose C-MGN and M-MGN, two monotone gradient neural network architectures for directly learning the gradients of convex functions.
- Categories:
38 Views
- Read more about Chord-Conditioned Melody Harmonization with Controllable Harmonicity
- Log in to post comments
Melody harmonization has long been closely associated with chorales composed by Johann Sebastian Bach. Previous works rarely emphasised chorale generation conditioned on chord progressions, and there has been a lack of focus on assistive compositional tools. In this paper, we first designed a music representation that encoded chord symbols for chord conditioning, and then proposed DeepChoir, a melody harmonization system that can generate a four-part chorale for a given melody conditioned on a chord progression.
- Categories:
12 Views
Point cloud completion aims to accurately estimate complete point clouds from partial observations. Existing methods often directly infer the missing points from the partial shape, but they suffer from limited structural information. To address this, we propose the Bilateral Coarse-to-Fine Network (BCFNet), which leverages 2D images as guidance to compensate for structural information loss. Our method introduces a multi-level codeword skip-connection to estimate structural details.
- Categories:
12 Views
- Read more about MEET: A Monte Carlo Exploration-Exploitation Trade-off for Buffer Sampling
- Log in to post comments
Data selection is essential for any data-based optimization technique, such as Reinforcement Learning. State-of-the-art sampling strategies for the experience replay buffer improve the performance of the Reinforcement Learning agent. However, they do not incorporate uncertainty in the Q-Value estimation. Consequently, they cannot adapt the sampling strategies, including exploration and exploitation of transitions, to the complexity of the task.
MEET_Poster.pdf
icassp_2023 (7).pdf
- Categories:
20 Views