
ICASSP 2022 - IEEE International Conference on Acoustics, Speech and Signal Processing is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The ICASSP 2022 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit the website.

- Read more about DCNGAN:A Deformable Convolution-Based GAN with QP Adaptation for Perceptual Quality Enhancement of Compressed Video
- Log in to post comments
In this paper, we propose a deformable convolution-based generative adversarial network (DCNGAN) for perceptual quality enhancement of compressed videos. DCNGAN is also adaptive to the quantization parameters (QPs). Compared with optical flows, deformable convolutions are more effective and efficient to align frames. Deformable convolutions can operate on multiple frames, thus leveraging more temporal information, which is beneficial for enhancing the perceptual quality of compressed videos.
- Categories:
 20 Views
20 Views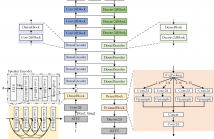
- Read more about DPCCN: Densely-Connected Pyramid Complex Convolutional Network for Robust Speech Separation And Extraction
- Log in to post comments
In recent years, a number of time-domain speech separation methods have been proposed. However, most of them are very sensitive to the environments and wide domain coverage tasks. In this paper, from the time-frequency domain perspective, we propose a densely-connected pyramid complex convolutional network, termed DPCCN, to improve the robustness of speech separation under complicated conditions. Furthermore, we generalize the DPCCN to target speech extraction (TSE) by integrating a new specially designed speaker encoder.
- Categories:
20 Views
- Read more about JMPNET: JOINT MOTION PREDICTION FOR LEARNING-BASED VIDEO COMPRESSION
- 1 comment
- Log in to post comments
- Categories:
16 Views
- Read more about Transient Analysis of Clustered Multitask Diffusion RLS Algorithm
- Log in to post comments
- Categories:
11 Views
- Read more about ROBUST DISENTANGLED VARIATIONAL SPEECH REPRESENTATION LEARNING FOR ZERO-SHOT VOICE CONVERSION
- Log in to post comments
Traditional studies on voice conversion (VC) have made progress with parallel training data and known speakers. Good voice conversion quality is obtained by exploring better alignment modules or expressive mapping functions. In this study, we investigate zero-shot VC from a novel perspective of self-supervised disentangled speech representation learning. Specifically, we achieve the disentanglement by balancing the information flow between global speaker representation and time-varying content representation in a sequential variational autoencoder (VAE).
- Categories:
30 Views
- Read more about Causal Alignment Based Fault Root Causes Localization for Wireless Network
- Log in to post comments
- Categories:
33 Views
- Read more about ChunkFusion: A Learning-based RGB-D 3D Reconstruction Framework via Chunk-wise Integration
- Log in to post comments
Recent years have witnessed a growing interest in online RGB-D 3D reconstruction. On the premise of ensuring the reconstruction accuracy with noisy depth scans, making the system scalable to various environments is still challenging. In this paper, we devote our efforts to try to fill in this research gap by proposing a scalable and robust RGB-D 3D reconstruction framework, namely ChunkFusion. In ChunkFusion, sparse voxel management is exploited to improve the scalability of online reconstruction.
- Categories:
20 Views
- Read more about REGULARIZED LATENT SPACE EXPLORATION FOR DISCRIMINATIVE FACE SUPER-RESOLUTION
- Log in to post comments
shi-poster.pdf
- Categories:
10 Views
- Read more about FORENSIC ANALYSIS AND LOCALIZATION OF MULTIPLY COMPRESSED MP3 AUDIO USING TRANSFORMERS
- Log in to post comments
Audio signals are often stored and transmitted in compressed formats. Among the many available audio compression schemes, MPEG-1 Audio Layer III (MP3) is very popular and widely used. Since MP3 is lossy it leaves characteristic traces in the compressed audio which can be used forensically to expose the past history of an audio file. In this paper, we consider the scenario of audio signal manipulation done by temporal splicing of compressed and uncompressed audio signals. We propose a method to find the temporal location of the splices based on transformer networks.
icassp_2022_poster.pdf
- Categories:
16 Views