
ICASSP 2022 - IEEE International Conference on Acoustics, Speech and Signal Processing is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The ICASSP 2022 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit the website.

- Read more about Temporal Knowledge Distillation for On-device Audio Classification
- Log in to post comments
- Categories:
 17 Views
17 Views
- Read more about Temporal Knowledge Distillation for On-device Audio Classification
- Log in to post comments
- Categories:
14 Views
- Read more about HOLISTIC SEMI-SUPERVISED APPROACHES FOR EEG REPRESENTATION LEARNING
- 1 comment
- Log in to post comments
- Categories:
23 Views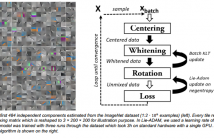
- Read more about LARGE-SCALE INDEPENDENT COMPONENT ANALYSIS BY SPEEDING UP LIE GROUP TECHNIQUES
- Log in to post comments
We were interested in computing a mini-batch-capable end-to end algorithm to identify statistically independent components (ICA) in large scale and high-dimensional datasets. Current algorithms typically rely on pre-whitened data and do not integrate the two procedures of whitening and ICA estimation. Our online approach estimates a whitening and a rotation matrix with stochastic gradient descent on centered or uncentered data. We show that this can be done efficiently by combining Batch Karhunen-Löwe-Transformation with Lie group techniques.
- Categories:
21 Views
- Read more about Acoustic comparison of physical vocal tract models with hard and soft walls
- Log in to post comments
This study explored how the frequencies and bandwidths of the acoustic resonances of physical tube models of the vocal tract differ when they have hard versus soft walls. For each of 10 tube shapes representing different vowels, two physical models were made: one with rigid plastic walls, and one with soft silicone walls. For all models, the acoustic transfer functions were measured and the bandwidths and frequencies of the first three resonances were determined.
- Categories:
12 Views
- Read more about Unsupervised Speech Enhancement with speech recognition embedding and disentanglement losses
- Log in to post comments
Speech enhancement has recently achieved great success with various
deep learning methods. However, most conventional speech enhancement
systems are trained with supervised methods that impose two
significant challenges. First, a majority of training datasets for speech
enhancement systems are synthetic. When mixing clean speech and
noisy corpora to create the synthetic datasets, domain mismatches
occur between synthetic and real-world recordings of noisy speech
or audio. Second, there is a trade-off between increasing speech
- Categories:
19 Views
- Read more about ImportantAug: A Data Augmentation Agent For Speech
- Log in to post comments
We introduce ImportantAug, a technique to augment training data
for speech classification and recognition models by adding noise
to unimportant regions of the speech and not to important regions.
Importance is predicted for each utterance by a data augmentation
agent that is trained to maximize the amount of noise it adds while
minimizing its impact on recognition performance. The effectiveness
of our method is illustrated on version two of the Google Speech
Commands (GSC) dataset. On the standard GSC test set, it achieves
- Categories:
23 Views
- Read more about Compression-aware Projection with Greedy Dimension Reduction for Activations
- Log in to post comments
Convolutional neural networks (CNNs) achieve remarkable performance in a wide range of fields. However, intensive memory access of activations introduces considerable energy consumption, impeding deployment of CNNs on resource-constrained edge devices. Existing works in activation compression propose to transform feature maps for higher compressibility, thus enabling dimension reduction. Nevertheless, in the case of aggressive dimension reduction, these methods lead to severe accuracy drop.
- Categories:
16 Views
- Read more about MUSIC IDENTIFICATION USING BRAIN RESPONSES TO INITIAL SNIPPETS
- Log in to post comments
Naturalistic music typically contains repetitive musical patterns that are present throughout the song. These patterns form a signature, enabling effortless song recognition. We investigate whether neural responses corresponding to these repetitive patterns also serve as a signature, enabling recognition of later song segments on learning initial segments. We examine EEG encoding of naturalistic musical patterns employing the NMED-T and MUSIN-G datasets.
- Categories:
22 Views