IEEE ICASSP 2024 - IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The IEEE ICASSP 2024 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit the website.
- Read more about ColorFlow_ICASSP2024
- 1 comment
- Log in to post comments
Image colorization is an ill-posed task, as objects within grayscale images can correspond to multiple colors, motivating researchers to establish a one-to-many relationship between objects and colors. Previous work mostly could only create an insufficient deterministic relationship. Normalizing flow can fully capture the color diversity from natural image manifold. However, classical flow often overlooks the color correlations between different objects, resulting in generating unrealistic color.
- Categories:
 50 Views
50 Views- Read more about On-Device Constrained Self-Supervised Learning for Keyword Spotting via Quantization Aware Pre-Training and Fine-tuning
- Log in to post comments
Large self-supervised models have excelled in various speech processing tasks, but their deployment on resource-limited devices is often impractical due to their substantial memory footprint. Previous studies have demonstrated the effectiveness of self-supervised pre-training for keyword spotting, even with constrained model capacity.
final_v5.pdf
- Categories:
34 Views- Read more about MDRT: MULTI-DOMAIN SYNTHETIC SPEECH LOCALIZATION
- Log in to post comments
With recent advancements in generating synthetic speech, tools to generate high-quality synthetic speech impersonating any human speaker are easily available. Several incidents report misuse of high-quality synthetic speech for spreading misinformation and for large-scale financial frauds. Many methods have been proposed for detecting synthetic speech; however, there is limited work on localizing the synthetic segments within the speech signal. In this work, our goal is to localize the synthetic speech segments in a partially synthetic speech signal.
mdrt_v05.pdf
- Categories:
37 Views- Read more about Boosting Speech Enhancement with Clean Self-Supervised Features Via Conditional Variational Autoencoders
- Log in to post comments
Recently, Self-Supervised Features (SSF) trained on extensive speech datasets have shown significant performance gains across various speech processing tasks. Nevertheless, their effectiveness in Speech Enhancement (SE) systems is often suboptimal due to insufficient optimization for noisy environments. To address this issue, we present a novel methodology that directly utilizes SSFs extracted from clean speech for enhancing SE models. Specifically, we leverage the clean SSFs for latent space modeling within the Conditional Variational Autoencoder (CVAE) framework.
- Categories:
37 Views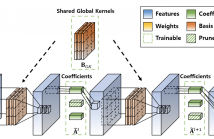
- Read more about G-SharP: Globally Shared Kernel with Pruning for Efficient CNNs
- Log in to post comments
Filter Decomposition (FD) methods have gained traction in compressing large neural networks by dividing weights into basis and coefficients. Recent advancements have focused on reducing weight redundancy by sharing either basis or coefficients stage-wise. However, traditional sharing approaches have overlooked the potential of sharing basis on a network-wide scale. In this study, we introduce an FD technique called G-SharP that elevates performance by using globally shared kernels throughout the network.
- Categories:
38 Views- Read more about Unsupervised Relapse Detection using Wearable-Based Digital Phenotyping for The 2nd E-Prevention Challenge
- Log in to post comments
This paper describes SRCB-LUL team's unsupervised relapse detection system submitted to the 2nd E-Prevention Challenge (Psychotic and Non-Psychotic Relapse Detection using Wearable-Based Digital Phenotyping). In our system, a person identification task is added to make the feature extraction network better distinguish between different behavior patterns. Three different structures of the feature extraction network are adopted. Then, the extracted features are used to train an Elliptic Envelope model of each patient for anomaly detection.
- Categories:
40 Views- Read more about slides for av2wav
- 1 comment
- Log in to post comments
Speech enhancement systems are typically trained using pairs of clean and noisy speech. In audio-visual speech enhancement
av2wav_pp.pptx
av2wav_pp.pptx
- Categories:
25 Views- Read more about Importance Sampling Based Unsupervised Federated Representation Learning
- Log in to post comments
The use of AI has led to the era of pervasive intelligence, marked by a proliferation of smart devices in our daily lives. Federated Learning (FL) enables machine learning at the edge without having to share user-specific private data with an untrusted third party. Conventional FL techniques are supervised learning methods, where a fundamental challenge is to ensure that data is reliably annotated at the edge. Another approach is to obtain rich and informative representations ofunlabeled data, which is suitable for downstream tasks.
- Categories:
24 Views- Read more about Privacy Preserving Federated Learning from Multi-input Functional Proxy Re-encryption
- Log in to post comments
Federated learning (FL) allows different participants to collaborate on model training without transmitting raw data, thereby protecting user data privacy. However, FL faces a series of security and privacy issues (e.g. the leakage of raw data from publicly shared parameters). Several privacy protection technologies, such as homomorphic encryption, differential privacy and functional encryption, are introduced for privacy enhancement in FL. Among them, the FL frameworks based on functional encryption better balance security and performance, thus receiving increasing attention.
- Categories:
38 Views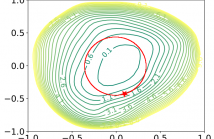
- Read more about BRINGING THE DISCUSSION OF MINIMA SHARPNESS TO THE AUDIO DOMAIN: A FILTER-NORMALISED EVALUATION FOR ACOUSTIC SCENE CLASSIFICATION
- Log in to post comments
The correlation between the sharpness of loss minima and generalisation in the context of deep neural networks has been subject to discussion for a long time. Whilst mostly investigated in the context of selected benchmark data sets in the area of computer vision, we explore this aspect for the acoustic scene classification task of the DCASE2020 challenge data. Our analysis is based on two-dimensional filter-normalised visualisations and a derived sharpness measure.
- Categories:
23 Views