- Transducers
- Spatial and Multichannel Audio
- Source Separation and Signal Enhancement
- Room Acoustics and Acoustic System Modeling
- Network Audio
- Audio for Multimedia
- Audio Processing Systems
- Audio Coding
- Audio Analysis and Synthesis
- Active Noise Control
- Auditory Modeling and Hearing Aids
- Bioacoustics and Medical Acoustics
- Music Signal Processing
- Loudspeaker and Microphone Array Signal Processing
- Echo Cancellation
- Content-Based Audio Processing

- Read more about FULLY COMPLEX DEEP NEURAL NETWORK FOR PHASE-INCORPORATING MONAURAL SOURCE SEPARATION
- Log in to post comments
- Categories:
 11 Views
11 Views- Read more about FULLY COMPLEX DEEP NEURAL NETWORK FOR PHASE-INCORPORATING MONAURAL SOURCE SEPARATION
- Log in to post comments
- Categories:
14 Views- Read more about : Faster-than-Nyquist Spatiotemporal Symbol-level Precoding in the Downlink of Multiuser MISO Channels
- Log in to post comments
- Categories:
14 Views
- Read more about Supervised group nonnegative matrix factorisation with similarity constraints and applications to speaker identification
- Log in to post comments
This paper presents supervised feature learning approaches for speaker identification that rely on nonnegative matrix factorisation. Recent studies have shown that group nonnegative matrix factorisation and task-driven supervised dictionary learning can help performing effective feature learning for audio classification problems.
- Categories:
7 Views- Read more about CODING OF FINE GRANULAR AUDIO SIGNALS USING HIGH RESOLUTION ENVELOPE PROCESSING (HREP)
- Log in to post comments
High Resolution Envelope Processing (HREP) is a new tool for improved perceptual coding of audio signals that predominantly consist of many dense transient events, such as applause, rain drop sounds, etc. These signals have traditionally been very difficult to code for perceptual audio codecs, particularly at low bit rates. Based on the gain control principle, HREP acts as a pre-/post-processor pair to perceptual audio codecs and preserves the temporal fine structure and subjective quality of applause-like signals.
- Categories:
64 Views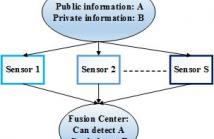
- Read more about MULTILAYER SENSOR NETWORK FOR INFORMATION PRIVACY
- Log in to post comments
A sensor network wishes to transmit information to a fusion center to allow it to detect a public hypothesis, but at the same time prevent it from inferring a private hypothesis. We propose a multilayer sensor network structure, where each sensor first applies a nonlinear fusion function on the information it receives from sensors in a previous layer, and then a linear weighting matrix to distort the information it sends to sensors in the next layer.
- Categories:
12 Views- Read more about BIOLOGICALLY INSPIRED SPEECH EMOTION RECOGNITION
- Log in to post comments
Conventional feature-based classification methods do not apply well to automatic recognition of speech emotions, mostly because the precise set of spectral and prosodic features that is required to identify the emotional state of a speaker has not been determined yet. This paper presents a method that operates directly on the speech signal, thus avoiding the problematic step of feature extraction.
- Categories:
48 Views- Read more about ROBUST AUTOMATIC RECOGNITION OF SPEECH WITH BACKGROUND MUSIC
- Log in to post comments
This paper addresses the task of Automatic Speech Recognition (ASR) with music in the background, where the accuracy of recognition may deteriorate significantly.
To improve the robustness of ASR in this task, e.g. for broadcast news transcription or subtitles creation, we adopt two approaches:
1) multi-condition training of the acoustic models and 2) denoising autoencoders followed by acoustic model training on the preprocessed data.
In the latter case, two types of autoencoders are considered: the fully connected and the convolutional network.
- Categories:
16 Views- Read more about Deductive Refinement of Species Labelling in Weakly Labelled Birdsong Recordings
- Log in to post comments
Many approaches have been used in bird species classification from their sound in order to provide labels for the whole of a recording. However, a more precise classification of each bird vocalization would be of great importance to the use and management of sound archives and bird monitoring. In this work, we introduce a technique that using a two step process can first automatically detect all bird vocalizations and then, with the use of ‘weakly’ labelled recordings, classify them.
- Categories:
10 Views