- Transducers
- Spatial and Multichannel Audio
- Source Separation and Signal Enhancement
- Room Acoustics and Acoustic System Modeling
- Network Audio
- Audio for Multimedia
- Audio Processing Systems
- Audio Coding
- Audio Analysis and Synthesis
- Active Noise Control
- Auditory Modeling and Hearing Aids
- Bioacoustics and Medical Acoustics
- Music Signal Processing
- Loudspeaker and Microphone Array Signal Processing
- Echo Cancellation
- Content-Based Audio Processing
- Read more about Application of Compressed Sensing to Wideband Spectrum Sensing in Cognitive Radio Networks
- Log in to post comments
- Categories:
 8 Views
8 ViewsSpeaker diarization in noisy conditions is addressed in this paper. The regression-based DNN is first adopted to map the noisy acoustic features to the clean features, and then consensus clustering of the original and mapped features is used to fuse the diarization results. The experiments are conducted on the IFLY-DIAR-II database, which is a Chinese talk show database with various noise types, such as music, applause and laughter. Compared to the baseline system using PLP features, a 21.26% relative DER improvement can be achieved using the proposed algorithm.
- Categories:
6 ViewsSpeaker diarization in noisy conditions is addressed in this paper. The regression-based DNN is first adopted to map the noisy acoustic features to the clean features, and then consensus clustering of the original and mapped features is used to fuse the diarization results. The experiments are conducted on the IFLY-DIAR-II database, which is a Chinese talk show database with various noise types, such as music, applause and laughter. Compared to the baseline system using PLP features, a 21.26% relative DER improvement can be achieved using the proposed algorithm.
- Categories:
23 ViewsIn this paper we describe approaches for discovering acoustic concepts and relations in text. The first major goal is to be able to identify text phrases which contain a notion of audibility and can be termed as a sound or an acoustic concept. We also propose a method to define an acoustic scene through a set of sound concepts. We use pattern matching and parts of speech tags to generate sound concepts from large scale text corpora. We use dependency parsing
- Categories:
16 Views- Read more about First Investigation of Universal Speech Attributes for Speaker Verification
- Log in to post comments
- Categories:
16 Views
- Read more about Graph-Based Active Learning: A New Look at Expected Error Minimization
- Log in to post comments
In graph-based active learning, algorithms based on expected error minimization (EEM) have been popular and yield good empirical performance.
The exact computation of EEM optimally balances exploration and exploitation.
In practice, however, EEM-based algorithms employ various approximations due to the computational hardness of exact EEM.
This can result in a lack of either exploration or exploitation, which can negatively impact the effectiveness of active learning.
- Categories:
15 Views
This paper investigates cyber-attacks compromising the data integrity of 100% inverter-interfaced islanded microgrids featuring an energy storage system (ESS), a wind turbine generator (WTG), a photovoltaic system (PV) and controllable loads. The ESS operates as the isochronous generator, responsible for forming the microgrid voltage and frequency, whereas the WTG and PV distributed energy resources (DER) operate in maximum-power-point-tracking (MPPT) mode.
- Categories:
12 Views
- Read more about On the Sum of Gamma-Gamma Variates with Application to the Fast Outage Probability Evaluation Over Fading Channels
- Log in to post comments
The Gamma-Gamma distribution has recently emerged in a number of applications ranging from modeling scattering and reverberation in sonar and radar systems to modeling atmospheric turbulence in wireless optical channels. In this respect, assessing the outage probability achieved by some diversity techniques over this kind of channels is of major practical importance. In many circumstances, this is intimately related to the difficult question of analyzing the statistics of a sum of Gamma-Gamma random variables. Answering this question is not a simple matter.
- Categories:
15 Views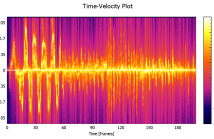
- Read more about Hidden Markov Model-based Gesture Recognition with FMCW Radar
- Log in to post comments
In this paper we present experimental results for the development
of a gesture recognition system using a 77 GHz FMCW
radar system. We measure the micro-Doppler signature of a
gesturing hand to construct an energy distribution in velocity
space over time. A gesturing hand is fundamentally a dynamical
system with unobservable “state” (i.e. the name of the gesture)
which determines the sequence of associated observable
velocity-energy distributions, so a Hidden Markov Model is
used to for gesture recognition, a more tailored approach than
- Categories:
50 Views
- Read more about CONSENSUS AND MULTIPLEX APPROACH FOR COMMUNITY DETECTION IN ATTRIBUTED NETWORKS
- Log in to post comments
An attributed network has nodes with attribute vectors. For community detection on an attributed network, we exploit the attributes to disentangle the potentially mixed topological structures. We describe a multiplex representation scheme for overlapping community detection in attributed networks and find consensus communities across layers of different connection structures. We test the method on Twitter, Facebook and Google+ networks and the results are comparable to state of the art. We show that the use of attribute vectors improves detection accuracy.
poster.pdf
- Categories:
12 Views