
ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The 2019 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit website.

- Read more about PERFORMANCE ANALYSIS OF DISCRETE-VALUED VECTOR RECONSTRUCTION BASED ON BOX-CONSTRAINED SUM OF L1 REGULARIZERS
- Log in to post comments
In this paper, we analyze the asymptotic performance of a convex optimization-based discrete-valued vector reconstruction from linear measurements. We firstly propose a box-constrained version of the conventional sum of absolute values (SOAV) optimization, which uses a weighted sum of L1 regularizers as a regularizer for the discrete-valued vector. We then derive the asymptotic symbol error rate (SER) performance of the box-constrained SOAV (Box-SOAV) optimization theoretically by using convex Gaussian min-max theorem.
- Categories:
 330 Views
330 Views
- Read more about Sample Space-Time Covariance Estimation
- Log in to post comments
Estimation errors are incurred when calculating the sample space-time covariance matrix. We formulate the variance of this estimator when operating on a finite sample set, compare it to known results, and demonstrate its precision in simulations. The variance of the estimation links directly to previously explored perturbation of the analytic eigenvalues and eigenspaces of a parahermitian cross-spectral density matrix when estimated from finite data.
icassp_2a.pdf
- Categories:
29 Views
- Read more about Aggregation Graph Neural Networks
- Log in to post comments
Graph neural networks (GNNs) regularize classical neural networks by exploiting the underlying irregular structure supporting graph data, extending its application to broader data domains. The aggregation GNN presented here is a novel GNN that exploits the fact that the data collected at a single node by means of successive local exchanges with neighbors exhibits a regular structure. Thus, regular convolution and regular pooling yield an appropriately regularized GNN.
- Categories:
44 Views
- Read more about MUSIC BOUNDARY DETECTION BASED ON A HYBRID DEEP MODEL OF NOVELTY, HOMOGENEITY, REPETITION AND DURATION
- Log in to post comments
Current state-of-the-art music boundary detection methods use local features for boundary detection, but such an approach fails to explicitly incorporate the statistical properties of the detected segments. This paper presents a music boundary detection method that simultaneously considers a fitness measure based on the boundary posterior probability, the likelihood of the segmentation duration sequence, and the acoustic consistency within a segment.
- Categories:
116 Views
- Read more about NON-INTRUSIVE SPEECH QUALITY ASSESSMENT USING NEURAL NETWORKS
- Log in to post comments
- Categories:
35 Views
ENF (Electric Network Frequency) oscillates around a nominal value (50/60 Hz) due to imbalance between consumed and generated power. The intensity of a light source powered by mains electricity varies depending on the ENF fluctuations. These fluctuations can be extracted from videos recorded in the presence of mains-powered source illumination. This work investigates how the quality of the ENF signal estimated from video is affected by different light source illumination, compression ratios, and by social media encoding.
- Categories:
193 Views
- Read more about Network Adaptation Strategies for Learning New Classes without Forgetting the Original Ones
- Log in to post comments
We address the problem of adding new classes to an existing classifier without hurting the original classes, when no access is allowed to any sample from the original classes. This problem arises frequently since models are often shared without their training data, due to privacy and data ownership concerns. We propose an easy-to-use approach that modifies the original classifier by retraining a suitable subset of layers using a linearly-tuned, knowledge-distillation regularization.
- Categories:
18 Views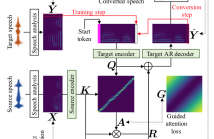
- Read more about AttS2S-VC: Sequence-to-Sequence Voice Conversion with Attention and Context Preservation Mechanisms
- Log in to post comments
This paper describes a method based on a sequence-to-sequence learning (Seq2Seq) with attention and context preservation mechanism for voice conversion (VC) tasks. Seq2Seq has been outstanding at numerous tasks involving sequence modeling such as speech synthesis and recognition, machine translation, and image captioning.
- Categories:
76 Views
- Read more about Securing smartphone handwritten PIN codes with recurrent neural networks
- Log in to post comments
- Categories:
54 Views