
ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The ICASSP 2020 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit website.

- Read more about Differentiable Branching in Deep Networks for Fast Inference
- Log in to post comments
In this paper, we consider the design of deep neural networks augmented with multiple auxiliary classifiers departing from the main (backbone) network. These classifiers can be used to perform early-exit from the network at various layers, making them convenient for energy-constrained applications such as IoT, embedded devices, or Fog computing. However, designing an optimized early-exit strategy is a difficult task, generally requiring a large amount of manual fine-tuning.
- Categories:
 113 Views
113 Views
- Read more about UNSUPERVISED AUTO-ENCODING MULTIPLE-OBJECT TRACKER FOR CONSTRAINT-CONSISTENT COMBINATORIAL PROBLEM
- Log in to post comments
Multiple-object tracking (MOT) and classification are core technologies for processing moving point clouds in radar or lidar applications. For accurate object classification, the one-to-one association relationship between the model of each objects' motion (trackers) and the observation sequences including auxiliary features (e.g., radar cross section) is important.
- Categories:
68 Views
- Read more about UNSUPERVISED AUTO-ENCODING MULTIPLE-OBJECT TRACKER FOR CONSTRAINT-CONSISTENT COMBINATORIAL PROBLEM
- Log in to post comments
Multiple-object tracking (MOT) and classification are core technologies for processing moving point clouds in radar or lidar applications. For accurate object classification, the one-to-one association relationship between the model of each objects' motion (trackers) and the observation sequences including auxiliary features (e.g., radar cross section) is important.
- Categories:
51 Views
- Read more about ESRGAN+ : Further Improving Enhanced Super-Resolution Generative Adversarial Network
- Log in to post comments
Enhanced Super-Resolution Generative Adversarial Network (ESRGAN) is a perceptual-driven approach for single image super-resolution that is able to produce photorealistic images. Despite the visual quality of these generated images, there is still room for improvement. In this fashion, the model is extended to further improve the perceptual quality of the images. We have designed a network architecture with a novel basic block to replace the one used by the original ESRGAN. Moreover, we introduce noise inputs to the generator network in order to exploit stochastic variation.
- Categories:
243 Views
- Read more about PHONEME BOUNDARY DETECTION USING LEARNABLE SEGMENTAL FEATURES
- Log in to post comments
Phoneme boundary detection plays an essential first step for a variety of speech processing applications such as speaker diarization, speech science, keyword spotting, etc. In this work, we propose a neural architecture coupled with a parameterized structured loss function to learn segmental representations for the task of phoneme boundary detection. First, we evaluated our model when the spoken phonemes were not given as input.
- Categories:
49 Views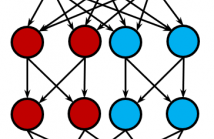
- Read more about An Efficient Alternative to Network Pruning through Ensemble Learning
- Log in to post comments
Convolutional Neural Networks (CNNs) currently represent the best tool for classification of image content. CNNs are trained in order to develop generalized expressions in form of unique features to distinguish different classes. During this process, one or more filter weights might develop the same or similar values. In this case, the redundant filters can be pruned without damaging accuracy.Unlike normal pruning methods, we investigate the possibility of replacing a full-sized convolutional neural network with an ensemble of its narrow versions.
- Categories:
75 Views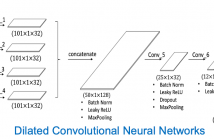
- Read more about Exploiting Vocal Tract Coordination Using Dilated CNNs for Depression Detection in Naturalistic Environments
- Log in to post comments
Depression detection from speech continues to attract significant research attention but remains a major challenge, particularly when the speech is acquired from diverse smartphones in natural environments. Analysis methods based on vocal tract coordination have shown great promise in depression and cognitive impairment detection for quantifying relationships between features over time through eigenvalues of multi-scale cross-correlations.
- Categories:
63 Views
- Read more about Approaching Optimal Embedding in Audio Steganography with GAN
- Log in to post comments
Audio steganography is a technology that embeds messages into audio without raising any suspicion from hearing it. Current steganography methods are based on heuristic cost designs. In this work, we proposed a framework based on Generative Adversarial Network (GAN) to approach optimal embedding for audio steganography in the temporal domain. This is the first attempt to approach optimal embedding with GAN and automatically learn the embedding probability/cost for audio steganography.
- Categories:
154 Views