
ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The ICASSP 2020 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit website.

- Read more about Source Coding of Audio Signals with a Generative Model
- 1 comment
- Log in to post comments
These are the slides from the video presentation at ICASSP 2020 of the paper "Source Coding of Audio Signals with a Generative Model".
- Categories:
 89 Views
89 Views
- Read more about Audio-based Detection of Explicit Content in Music
- Log in to post comments
We present a novel automatic system for performing explicit content detection directly on the audio signal. Our modular approach uses an audio-to-character recognition model, a keyword spotting model associated with a dictionary of carefully chosen keywords, and a Random Forest classification model for the final decision. To the best of our knowledge, this is the first explicit content detection system based on audio only. We demonstrate the individual relevance of our modules on a set of sub-tasks and compare our approach to a lyrics-informed oracle and an end-to-end naive architecture.
- Categories:
82 Views
- Read more about Spiking neural networks trained with backpropagation for low power neuromorphic implementation of voice activity detection
- Log in to post comments
Recent advances in Voice Activity Detection (VAD) are driven by artificial and Recurrent Neural Networks (RNNs), however, using a VAD system in battery-operated devices requires further power efficiency. This can be achieved by neuromorphic hardware, which enables Spiking Neural Networks (SNNs) to perform inference at very low energy consumption. Spiking networks are characterized by their ability to process information efficiently, in a sparse cascade of binary events in time called spikes.
- Categories:
123 Views
- Read more about I-VECTOR TRANSFORMATION USING K-NEAREST NEIGHBORS FOR SPEAKER VERIFICATION
- Log in to post comments
- Categories:
34 Views
- Read more about VOICE BASED CLASSIFICATION OF PATIENTS WITH AMYOTROPHIC LATERAL SCLEROSIS, PARKINSON'S DISEASE AND HEALTHY CONTROLS WITH CNN-LSTM USING TRANSFER LEARNING
- Log in to post comments
In this paper, we consider 2-class and 3-class classification problems for classifying patients with Amyotropic Lateral Sclerosis (ALS), Parkinson’s Disease (PD) and Healthy Controls (HC) using a CNN-LSTM network. Classification performance is examined for three different tasks, namely, Spontaneous speech (SPON), Diadochoki-netic rate (DIDK) and Sustained Phonation (PHON). Experiments are conducted using speech data recorded from 60 ALS, 60 PD and60 HC subjects. Classification using SVM and DNN are considered baseline schemes.
- Categories:
87 Views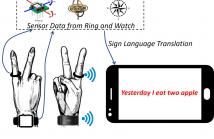
- Read more about Application Informed Motion Signal Processing for Finger Motion Tracking Using Wearable Sensors
- Log in to post comments
- Categories:
68 Views
- Read more about SPEECH RECOGNITION MODEL COMPRESSION
- Log in to post comments
Deep Neural Network-based speech recognition systems are widely used in most speech processing applications. To achieve better model robustness and accuracy, these networks are constructed with millions of parameters, making them storage and compute-intensive. In this paper, we propose Bin & Quant (B&Q), a compression technique using which we were able to reduce the Deep Speech 2 speech recognition model size by 7 times for a negligible loss in accuracy.
- Categories:
54 Views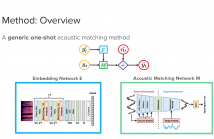
- Read more about Acoustic Matching by Embedding Impulse Responses
- Log in to post comments
The goal of acoustic matching is to transform an audio recording made in one acoustic environment to sound as if it had been recorded in a different environment, based on reference audio from the target environment. This paper introduces a deep learning solution for two parts of the acoustic matching problem. First, we characterize acoustic environments by mapping audio into a low-dimensional embedding invariant to speech content and speaker identity.
- Categories:
57 Views
- Read more about CROSS LINGUAL TRANSFER LEARNING FOR ZERO-RESOURCE DOMAIN ADAPTATION
- Log in to post comments
We propose a method for zero-resource domain adaptation of DNN acoustic models, for use in low-resource situations where the only in-language training data available may be poorly matched to the intended target domain. Our method uses a multi-lingual model in which several DNN layers are shared between languages. This architecture enables domain adaptation transforms learned for one well-resourced language to be applied to an entirely different low- resource language.
- Categories:
25 Views
- Categories:
36 Views