
ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The ICASSP 2020 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit website.
- Read more about Particle Filtering on the Complex Stiefel Manifold with Application to Subspace Tracking
- Log in to post comments
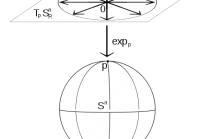
In this paper, we extend previous particle filtering methods whose states were constrained to the (real) Stiefel manifold to the complex case. The method is then applied to a Bayesian formulation of the subspace tracking problem. To implement the proposed particle filter, we modify a previous MCMC algorithm so as to simulate from densities defined on the complex manifold. Also, to compute subspace estimates from particle approximations, we extend existing averaging methods to complex Grassmannians.
slides.pdf
- Categories:
 131 Views
131 Views
Neural network language model (NNLM) is an essential component of industrial ASR systems. One important challenge of training an NNLM is to leverage between scaling the learning process and handling big data. Conventional approaches such as block momentum provides a blockwise model update filtering (BMUF) process and achieves almost linear speedups with no performance degradation for speech recognition.
- Categories:
65 Views
- Read more about LEAK DETECTION OF SPACECRAFT IN ORBIT USING ULTRASONIC SENSOR ARRAY BY LAMB WAVES
- Log in to post comments
With the increasing of human space activities, the number of space debris has increased dramatically, the possibility that spacecraft in orbit is impacted by space debris is growing. It is important to detect and locate the gas leak accurately and timely. In this paper, a leak detection method using ultrasonic sensor array is proposed. Firstly, the ultrasonic sensor array is used to detect the leak acoustic signal which propagates as Lamb wave through spacecraft structure. Then we apply beam forming algorithm to determine the direction of the leak source.
- Categories:
68 Views
- Read more about ENHANCE FEATURE REPRESENTATION OF ELECTROENCEPHALOGRAM FOR SEIZURE DETECTION
- Log in to post comments
In the treatment of epilepsy with intracranial electroencephalogram(iEEG), the recognition accuracy is low, and it is
difficult to find the correlation between channels because of the large amount of channel numbers and time series data. In
order to solve these problems, we propose a novel EEG feature prepresentation method for seizure detection based on the
Log Mel-Filterbank energy feature. We propose to adapt the Mel-Filterbank energy to EEG features with logrithm transform
- Categories:
58 Views
- Read more about Performance Bounds for Displaced Sensor Automotive Radar Imaging
- Log in to post comments
In automotive radar imaging, displaced sensors offer improvement in localization accuracy by jointly processing the data acquired from multiple radar units, each of which may have limited individual resources. In this paper, we derive performance bounds on the estimation error of target parameters processed by displaced sensors that correspond to several independent radars mounted at different locations on the same vehicle. Unlike previous studies, we do not assume a very accurate time synchronization among the sensors.
- Categories:
26 Views
- Read more about An Empirical Bayes Approach to Partially Labeled and Shuffled Data Sets
- 1 comment
- Log in to post comments
This work outlines a method for an application of empirical Bayes in the setting of semi-supervised learning. That is, we consider a scenario in which the training set is partially or entirely unlabeled. In addition to the missing labels, we also consider a scenario where the available training data might be shuffled (i.e., the features and labels are not matched).
ICASSP.pdf
- Categories:
65 Views
- Read more about A Self-Attentive Emotion Recognition Network
- Log in to post comments
Attention networks constitute the state-of-the-art paradigm for capturing long temporal dynamics. This paper examines the efficacy of this paradigm in the challenging task of emotion recognition in dyadic conversations. In this work, we introduce a novel attention mechanism capable of inferring the immensity of the effect of each past utterance on the current speaker emotional state.
- Categories:
29 Views
- Read more about text-independent speaker verfication with adversarial learning on short utterances
- Log in to post comments
- Categories:
87 Views
- Read more about MULTI-STAGE RESIDUAL HIDING FOR IMAGE-INTO-AUDIO STEGANOGRAPHY
- Log in to post comments
The widespread application of audio communication technologies has speeded up audio data flowing across the Internet, which made it an popular carrier for covert communication. In this paper, we present a cross-modal steganography method for hiding image content into audio carriers while preserving the perceptual fidelity of the cover audio.
- Categories:
135 Views
- Read more about Exploring Energy Efficient Quantum-resistant Signal Processing Using Array Processors
- Log in to post comments
Quantum computers threaten to break public-key cryptography schemes such as DSA and ECDSA in polynomial time, which poses an imminent threat to secure signal processing.
Ring learning with error (RLWE) lattice-based cryptography (LBC) is one of the most promising families of post-quantum cryptography (PQC) schemes in terms of efficiency and versatility. Two conventional methods to compute polynomial multiplication, the most compute-intensive routine in the RLWE schemes, are convolutions and Number Theoretic Transform (NTT).
- Categories:
23 Views