
ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The ICASSP 2020 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit website.
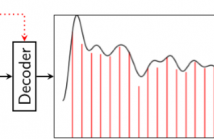
- Read more about VaPar Synth - A Variational Parametric Model for Audio Synthesis
- 1 comment
- Log in to post comments
With the advent of data-driven statistical modeling and abundant computing power, researchers are turning increasingly to deep learning for audio synthesis. These methods try to model audio signals directly in the time or frequency domain. In the interest of more flexible control over the generated sound, it could be more useful to work with a parametric representation of the signal which corresponds more directly to the musical attributes such as pitch, dynamics and timbre.
- Categories:
 57 Views
57 Views
- Read more about Non-Experts or Experts? Statistical Analyses of MOS using DSIS Method
- Log in to post comments
In image quality assessments, the results of subjective evaluation experiments that use the double-stimulus impairment scale (DSIS) method are often expressed in terms of the mean opinion score (MOS), which is the average score of all subjects for each test condition. Some MOS values are used to derive image quality criteria, and it has been assumed that it is preferable to perform tests with non-expert subjects rather than with experts. In this study, we analyze the results of several subjective evaluation experiments using the DSIS method.
- Categories:
27 Views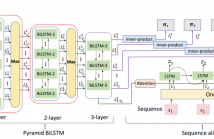
- Read more about Key Action And Joint CTC-Attention Based Sign Language Recognition
- Log in to post comments
Sign Language Recognition (SLR) translates sign language video into natural language. In practice, sign language video, owning a large number of redundant frames, is necessary to be selected the essential. However, unlike common video that describes actions, sign language video is characterized as continuous and dense action sequence, which is difficult to capture key actions corresponding to meaningful sentence. In this paper, we propose to hierarchically search key actions by a pyramid BiLSTM.
- Categories:
59 Views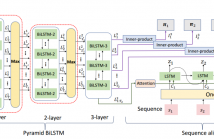
- Read more about Key Action And Joint CTC-Attention Based Sign Language Recognition
- Log in to post comments
Sign Language Recognition (SLR) translates sign language video into natural language. In practice, sign language video, owning a large number of redundant frames, is necessary to be selected the essential. However, unlike common video that describes actions, sign language video is characterized as continuous and dense action sequence, which is difficult to capture key actions corresponding to meaningful sentence. In this paper, we propose to hierarchically search key actions by a pyramid BiLSTM.
- Categories:
99 Views
- Read more about Estimating Structural Missing Values via Low-tubal-rank Tensor Completion
- Log in to post comments
The recently proposed Tensor Nuclear Norm (TNN) minimization has been widely used for tensor completion. However, previous works didn’t consider the structural difference between the observed data and missing data, which widely exists in many applications. In this paper, we propose to incorporate a constraint item on the missing values into low-tubal-rank tensor completion to promote the structural hypothesis
- Categories:
58 Views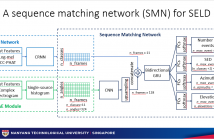
- Read more about A Sequence Matching Network for Polyphonic Sound Event Localization and Detection
- Log in to post comments
Polyphonic sound event detection and direction-of-arrival estimation require different input features from audio signals. While sound event detection mainly relies on time-frequency patterns, direction-of-arrival estimation relies on magnitude or phase differences between microphones. Previous approaches use the same input features for sound event detection and direction-of-arrival estimation, and train the two tasks jointly or in a two-stage transfer-learning manner.
- Categories:
77 Views
- Read more about AN IMPROVED DEEP NEURAL NETWORK FOR MODELING SPEAKER CHARACTERISTICS AT DIFFERENT TEMPORAL SCALES
- Log in to post comments
This paper presents an improved deep embedding learning method based on a convolutional neural network (CNN) for text-independent speaker verification. Two improvements are proposed for x-vector embedding learning: (1) a multiscale convolution (MSCNN) is adopted in the frame-level layers to capture the complementary speaker information in different receptive fields; (2) a Baum-Welch statistics attention (BWSA) mechanism is applied in the pooling layer, which can integrate more useful long-term speaker characteristics in the temporal pooling layer.
- Categories:
26 Views
- Read more about Source Coding of Audio Signals with a Generative Model
- 2 comments
- Log in to post comments
We consider source coding of audio signals with the help of a generative model. We use a construction where a waveform is first quantized, yielding a finite bitrate representation. The waveform is then reconstructed by random sampling from a model conditioned on the quantized waveform. The proposed coding scheme is theoretically analyzed. Using SampleRNN as the generative model, we demonstrate that the proposed coding structure provides performance competitive with state-of-the-art source coding tools for specific categories of audio signals.
- Categories:
135 Views
- Read more about SPECTROGRAMS FUSION WITH MINIMUM DIFFERENCE MASKS ESTIMATION FOR MONAURAL SPEECH DEREVERBERATION
- Log in to post comments
Spectrograms fusion is an effective method for incorporating complementary speech dereverberation systems. Previous linear spectrograms fusion by averaging multiple spectrograms shows outstanding performance. However, various systems with different features cannot apply this simple method. In this study, we design the minimum difference masks (MDMs) to classify the time-frequency (T-F) bins in spectrograms according to the nearest distances from labels. Then, we propose a two-stage nonlinear spectrograms fusion system for speech dereverberation.
- Categories:
52 Views