
ICASSP 2022 - IEEE International Conference on Acoustics, Speech and Signal Processing is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The ICASSP 2022 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit the website.

- Read more about Parametric Modeling of Human Wrist for Bioimpedance-based Physiological Sensing
- Log in to post comments
Bioimpedance is a powerful modality to continuously and non-invasively monitor cardiovascular and respiratory health parameters through the wearable operation. However, for bioimpedance sensors to be utilized in medical-grade settings, the reliability and robustness of the system should be improved. Previous studies provide limited fundamental analyses of the factors involved in the system that impact the sensitivity and the specificity of the modality in capturing the hemodynamics.
- Categories:
 19 Views
19 Views
- Read more about Unsupervised Audio-Caption Aligning Learns Correspondences between Individual Sound Events and Textual Phrases
- Log in to post comments
We investigate unsupervised learning of correspondences between sound events and textual phrases through aligning audio clips with textual captions describing the content of a whole audio clip. We align originally unaligned and unannotated audio clips and their captions by scoring the similarities between audio frames and words, as encoded by modality-specific encoders and using a ranking-loss criterion to optimize the model.
- Categories:
29 Views
- Read more about Watermarking images in self-supervised latent-spaces - poster
- Log in to post comments
- Categories:
14 Views
- Read more about Watermarking images in self-supervised latent-spaces - slides
- Log in to post comments
- Categories:
9 Views
- Read more about On loss functions and evaluation metrics for music source separation
- Log in to post comments
We investigate which loss functions provide better separations via
benchmarking an extensive set of those for music source separation.
To that end, we first survey the most representative audio source
separation losses we identified, to later consistently benchmark them
in a controlled experimental setup. We also explore using such losses
as evaluation metrics, via cross-correlating them with the results of
a subjective test. Based on the observation that the standard signal-
to-distortion ratio metric can be misleading in some scenarios, we
- Categories:
100 Views
- Read more about TOWARDS FASTER CONTINUOUS MULTI-CHANNEL HRTF MEASUREMENTS BASED ON LEARNING SYSTEM MODELS
- Log in to post comments
Measuring personal head-related transfer functions (HRTFs) is essential in binaural audio. Personal HRTFs are not only required for binaural rendering and for loudspeaker-based binaural reproduction using crosstalk cancellation, but they also serve as a basis for data-driven HRTF individualization techniques and psychoacoustic experiments. Although many attempts have been made to expedite HRTF measurements, the rotational velocities in today’s measurement systems remain lower than those in natural head movements.
- Categories:
27 Views
- Read more about UniSpeech-SAT: Universal Speech Representation Learning with Speaker Aware Pre-Training
- Log in to post comments
- Categories:
178 Views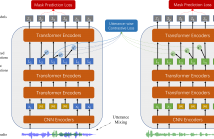
- Read more about UniSpeech-SAT: Universal Speech Representation Learning with Speaker Aware Pre-Training
- Log in to post comments
- Categories:
128 Views
- Read more about Cramèr-Rao Bound for Estimation After Model Selection and its Application to Sparse Vector Estimation
- Log in to post comments
In many practical parameter estimation problems,
such as coefficient estimation of polynomial regression, the true
model is unknown and thus, a model selection step is performed
prior to estimation. The data-based model selection step affects
the subsequent estimation. In particular, the oracle Cramér-Rao
bound (CRB), which is based on knowledge of the true model, is
inappropriate for post-model-selection performance analysis and
system design outside the asymptotic region. In this paper, we
- Categories:
8 Views