
ICASSP 2022 - IEEE International Conference on Acoustics, Speech and Signal Processing is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The ICASSP 2022 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit the website.
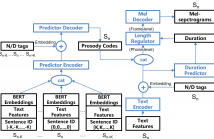
- Read more about DISCOURSE-LEVEL PROSODY MODELING WITH A VARIATIONAL AUTOENCODER FOR NON-AUTOREGRESSIVE EXPRESSIVE SPEECH SYNTHESIS
- Log in to post comments
To address the issue of one-to-many mapping from phoneme sequences to acoustic features in expressive speech synthesis, this paper proposes a method of discourse-level prosody modeling with a variational autoencoder (VAE) based on the non-autoregressive architecture of FastSpeech. In this method, phone-level prosody codes are extracted from prosody features by combining VAE with FastSpeech, and are predicted using discourse-level text features together with BERT embeddings. The continuous wavelet transform (CWT) in FastSpeech2 for F0 representation is not necessary anymore.
ppt.pptx
- Categories:
 36 Views
36 Views
- Read more about Tackling Data Scarcity in Speech Translation Using Zero-Shot Multilingual Machine Translation Techniques
- Log in to post comments
Recently, end-to-end speech translation (ST) has gained significant attention as it avoids error propagation. However, the approach suffers from data scarcity. It heavily depends on direct ST data and is less efficient in making use of speech transcription and text translation data, which is often more easily available. In the related field of multilingual text translation, several techniques have been proposed for zero-shot translation. A main idea is to increase the similarity of semantically similar sentences in different languages.
- Categories:
67 Views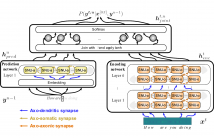
- Read more about Speech Recognition Using Biologically-Inspired Neural Networks
- Log in to post comments
Automatic speech recognition systems (ASR), such as the recurrent neural network transducer (RNN-T), have reached close to human-like performance and are deployed in commercial applications. However, their core operations depart from the powerful biological counterpart, the human brain. On the other hand, the current developments in biologically-inspired ASR models lag behind in terms of accuracy and focus primarily on small-scale applications.
- Categories:
20 Views
- Read more about Towards Robust Visual Transformer Networks via K-Sparse Attention
- Log in to post comments
Transformer networks, originally developed in the community of machine translation to eliminate sequential nature of recurrent neural networks, have shown impressive results in other natural language processing and machine vision tasks. Self-attention is the core module behind visual transformers which globally mixes the image information. This module drastically reduces the intrinsic inductive bias imposed by CNNs, such as locality, while encountering insufficient robustness against some adversarial attacks.
- Categories:
39 Views
- Read more about THE EFFECT OF PARTIAL TIME-FREQUENCY MASKING OF THE DIRECT SOUND ON THE PERCEPTION OF REVERBERANT SPEECH
- Log in to post comments
The perception of sound in real-life acoustic environments, such as enclosed rooms or open spaces with reflective objects, is affected by reverberation. Hence, reverberation is extensively studied in the context of auditory perception, with many studies highlighting the importance of the direct sound for perception. Based on this insight, speech processing methods often use time-frequency (TF) analysis to detect TF bins that are dominated by the direct sound, and then use the detected bins to reproduce or enhance the speech signals.
- Categories:
12 Views
- Read more about Deep Hashing With Hash Center Update for Efficient Image Retrieval
- 1 comment
- Log in to post comments
In this paper, we propose an approach for learning binary hash codes
for image retrieval. Canonical Correlation Analysis (CCA) is used
to design two loss functions for training a neural network such that
the correlation between the two views to CCA is maximum. The
main motivation for using CCA for feature space learning is that
dimensionality reduction is possible and short binary codes could
be generated. The first loss maximizes the correlation between the
hash centers and the learned hash codes. The second loss maximizes
4514-2.pdf
- Categories:
25 Views
In this paper, we focus on learning sparse graphs with a core-periphery structure. We propose a generative model for data associated with core-periphery structured networks to model the dependence of node attributes on core scores of the nodes of a graph through a latent graph structure. Using the proposed model, we jointly infer a sparse graph and nodal core scores that induce dense (sparse) connections in core (respectively, peripheral) parts of the network.
- Categories:
20 Views
- Read more about MTAF: SHOPPING GUIDE MICRO-VIDEOS POPULARITY PREDICTION USING MULTIMODAL AND TEMPORAL ATTENTION FUSION APPROACH
- Log in to post comments
Predicting the popularity of shopping guide micro-videos incorporating merchandise is crucial for online advertising. What are the significant factors affecting the popularity of the micro-video? How to extract and effectively fuse multiple modalities for the micro-video popularity prediction? This is a question that needs to be urgently answered to better provide insights for advertisers. In this paper, we propose a Multimodal and Temporal Attention Fusion (MTAF) framework to represent and combine multi-modal features.
- Categories:
31 Views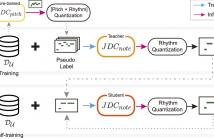
- Read more about PSEUDO-LABEL TRANSFER FROM FRAME-LEVEL TO NOTE-LEVEL IN A TEACHER-STUDENT FRAMEWORK FOR SINGING TRANSCRIPTION FROM POLYPHONIC MUSIC
- Log in to post comments
Lack of large-scale note-level labeled data is the major obstacle to singing transcription from polyphonic music. We address the issue by using pseudo labels from vocal pitch estimation models given unlabeled data. The proposed method first converts the frame-level pseudo labels to note-level through pitch and rhythm quantization steps. Then, it further improves the label quality through self-training in a teacher-student framework.
- Categories:
25 Views