
ICASSP 2022 - IEEE International Conference on Acoustics, Speech and Signal Processing is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The ICASSP 2022 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit the website.

- Read more about Path signatures for non-intrusive load monitoring
- Log in to post comments
- Categories:
 29 Views
29 Views

- Read more about Custom attribution loss for improving generalization and interpretability of deepfake detection
- Log in to post comments
The simplicity and accessibility of tools for generating deepfakes pose a significant technical challenge for their detection and filtering. Many of the recently proposed methods for deeptake detection focus on a `blackbox' approach and therefore suffer from the lack of any additional information about the nature of fake videos beyond the fake or not fake labels. In this paper, we approach deepfake detection by solving the related problem of attribution, where the goal is to distinguish each separate type of a deepfake attack.
- Categories:
10 Views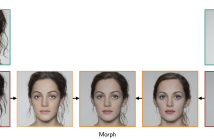
- Read more about Are GAN-based Morphs Threatening Face Recognition?
- Log in to post comments
Morphing attacks are a threat to biometric systems where the biometric reference in an identity document can be altered. This form of attack presents an important issue in applications relying on identity documents such as border security or access control. Research in generation of face morphs and their detection is developing rapidly, however very few datasets with morphing attacks and open-source detection toolkits are publicly available.
- Categories:
30 Views
- Read more about A ROBUST DEEP AUDIO SPLICING DETECTION METHOD VIA SINGULARITY DETECTION FEATURE
- Log in to post comments
There are many methods for detecting forged audio produced by conversion and synthesis. However, as a simpler method of forgery, splicing has not attracted widespread attention.
Based on the characteristic that the tampering operation will cause singularities at high-frequency components, we propose a high-frequency singularity detection feature obtained
- Categories:
23 Views
- Read more about A ROBUST DEEP AUDIO SPLICING DETECTION METHOD VIA SINGULARITY DETECTION FEATURE
- Log in to post comments
There are many methods for detecting forged audio produced by conversion and synthesis. However, as a simpler method of forgery, splicing has not attracted widespread attention.
Based on the characteristic that the tampering operation will cause singularities at high-frequency components, we propose a high-frequency singularity detection feature obtained
- Categories:
21 Views
- Read more about SERAB: A MULTI-LINGUAL BENCHMARK FOR SPEECH EMOTION RECOGNITION
- Log in to post comments
The Speech Emotion Recognition Adaptation Benchmark (SERAB) is a new framework to evaluate the performance and generalization capacity of different approaches for utterance-level SER. The benchmark is composed of nine datasets for SER in six languages. We used the proposed framework to evaluate a selection of standard hand-crafted feature sets and state-of-the-art DNN representations. The results highlight that using only a subset of the data included in SERAB can result in biased evaluation, while compliance with the proposed protocol can circumvent this issue.
- Categories:
19 Views
- Read more about THE DAWN OF QUANTUM NATURAL LANGUAGE PROCESSING
- Log in to post comments
In this paper, we discuss the initial attempts at boosting understanding of human language based on deep-learning models with quantum computing. We successfully train a quantum-enhanced Long Short-Term Memory network to perform the parts-of-speech tagging task via numerical simulations. Moreover, a quantum-enhanced Transformer is proposed to perform the sentiment analysis based on the existing dataset.
- Categories:
7 Views
- Read more about "DYNAMIC RESOURCEOPTIMIZATION FORADAPTIVE FEDERATED LEARNING EMPOWERED BY RECONFIGURABLE INTELLIGENT SURFACES" Poster
- Log in to post comments
The aim of this work is to propose a novel dynamic resource allocation strategy for adaptive Federated Learning (FL), in the context of beyond 5G networks endowed with Reconfigurable Intelligent Surfaces (RISs). Due to time-varying wireless channel conditions, communication resources (e.g., set of transmitting devices, transmit powers, bits), computation parameters (e.g., CPU cycles at devices and at server) and RISs reflectivity must be optimized in each communication round, in order to strike the best trade-off between power, latency, and performance of the FL task.
- Categories:
8 Views