
The International Conference on Image Processing (ICIP), sponsored by the IEEE Signal Processing Society, is the premier forum for the presentation of technological advances and research results in the fields of theoretical, experimental, and applied image and video processing. ICIP has been held annually since 1994, brings together leading engineers and scientists in image and video processing from around the world. Visit website.

- Read more about Regularized Gradient Descent Training of Steered Mixture of Experts for Sparse Image Representation
- Log in to post comments
The Steered Mixture-of-Experts (SMoE) framework targets a sparse space-continuous representation for images, videos, and light fields enabling processing tasks such as approximation, denoising, and coding.
The underlying stochastic processes are represented by a Gaussian Mixture Model, traditionally trained by the Expectation-Maximization (EM) algorithm.
We instead propose to use the MSE of the regressed imagery for a Gradient Descent optimization as primary training objective.
- Categories:
 23 Views
23 Views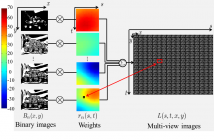
We propose an efficient coding scheme for a dense light field, i.e.,
a set of multi-viewpoint images taken with very small viewpoint intervals.
The key idea behind our proposal is that a light field is represented
only using weighted binary images, where several binary
images and corresponding weight values are to be chosen to optimally
approximate the light field. The coding scheme derived from
this idea is completely different from those of modern image/video
coding standards. However, we found that our scheme can achieve
- Categories:
29 Views
- Read more about MULTI-EXPOSURE FUSION WITH CNN FEATURES
- Log in to post comments
- Categories:
28 Views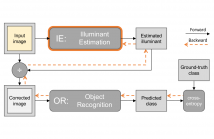
In this paper we present a deep learning method to estimate the illuminant of an image. Our model is not trained with illuminant annotations, but with the objective of improving performance on an auxiliary task such as object recognition. To the best of our knowledge, this is the first example of a deep learning architecture for illuminant estimation that is trained without ground truth illuminants. We evaluate our solution on standard datasets for color constancy, and compare it with state of the art methods.
- Categories:
9 Views
- Read more about CYCLIC ANNEALING TRAINING CONVOLUTIONAL NEURAL NETWORKS FOR IMAGE CLASSIFICATION WITH NOISY LABELS
- Log in to post comments
Noisy labels modeling makes a convolutional neural network (CNN) more robust for the image classification problem. However, current noisy labels modeling methods usually require an expectation-maximization (EM) based procedure to optimize the parameters, which is computationally expensive. In this paper, we utilize a fast annealing training method to speed up the CNN training in every M-step.
- Categories:
36 Views
This paper proposes a novel approach for colorizing near infrared (NIR) images using a S-shape network (SNet). The proposed approach is based on the usage of an encoder-decoder architecture followed with a secondary assistant network. The encoder-decoder consists of a contracting path to capture context and a symmetric expanding path that enables precise localization. The assistant network is a shallow
- Categories:
44 Views
- Read more about DEPTH ESTIMATION NETWORK FOR DUAL DEFOCUSED IMAGES WITH DIFFERENT DEPTH-OF-FIELD
- Log in to post comments
In this work, we propose an algorithm to estimate the depth map of a scene using defocused images. In particular, the depth map is estimated using two defocused images with different depth-of-field for the same scene. Similar to the approach of the general depth from defocus (DFD), the proposed algorithm obtains the depth information from the
- Categories:
48 Views
- Read more about Class-specific Coders for Hyper-spectral Image Classification
- Log in to post comments
In this paper, we introduce the paradigm of class specific
coders (CSC) for classification of hyperspectral images
(HSI). Apparently, CSC are defined as a set of distinct
encoder-decoder (henceforth called a coder) networks where
a given coder is trained on the samples of a particular class.
In contrast to auto-encoders (AE) which learn an identity
mapping of data in an unsupervised fashion, the CSC model,
on the other hand, learns re-constructive mappings for all
possible pairs of training samples for each class in separate
- Categories:
24 Views
- Read more about IMAGE STITCHING FOR DUAL FISHEYE CAMERAS
- Log in to post comments
Panoramic photography creates stunning immersive visual experiences for viewers. In this paper, we investigate how to seamlessly stitch a pair of images captured by two uncalibrated, back-to-back, 195-degree fisheye cameras to generate a surround view of a 3D scene. It is a challenging task because the two camera centers are displaced and because the common region is the most distorted area. To enhance the robustness of feature matching and hence the quality of stitching, we propose a novel technique that projects the image rectilinearly onto an equirectangular plane.
Poster.pdf
- Categories:
145 Views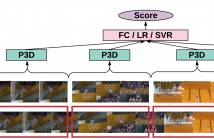
- Read more about S3D: Stacking Segmental P3D for Action Quality Assessment
- 1 comment
- Log in to post comments
Action quality assessment is crucial in areas of sports, surgery and assembly line where action skills can be evaluated. In this paper, we propose the Segment-based P3D-fused network S3D built-upon ED-TCN and push the performance on the UNLV-Dive dataset by a significant margin. We verify that segment-aware training performs better than full-video training which turns out to focus on the water spray. We show that temporal segmentation can be embedded with few efforts.
- Categories:
107 Views