
ICIP 2020 is a fully virtual conference. The International Conference on Image Processing (ICIP), sponsored by the IEEE Signal Processing Society, is the premier forum for the presentation of technological advances and research results in the fields of theoretical, experimental, and applied image and video processing. ICIP has been held annually since 1994, brings together leading engineers and scientists in image and video processing from around the world. Visit website.

- Read more about Spatial Keyframe Extraction of Mobile Videos for Efficient Object Detection at the Edge
- Log in to post comments
Advances in federated learning and edge computing advocate for deep learning models to run at edge devices for video analysis. However, the captured video frame rate is too high to be processed at the edge in real-time with a typical model such as CNN. Any approach to consecutively feed frames to the model compromises both the quality (by missing important frames) and the efficiency (by processing redundantly similar frames) of analysis.
ICIP2020.pdf
- Categories:
 18 Views
18 Views
- Read more about Kernelized Dense Layers For Facial Expression Recognition
- 1 comment
- Log in to post comments
Fully connected layer is an essential component of Convolutional Neural Networks (CNNs), which demonstrates its efficiency in computer vision tasks. The CNN process usually starts with convolution and pooling layers that first break down the input images into features, and then analyze them independently. The result of this process feeds into a fully connected neural network structure which drives the final classification decision. In this paper, we propose a Kernelized Dense Layer (KDL) which captures higher order feature interactions instead of conventional linear relations.
- Categories:
15 Views
- Read more about CDVA/VCM: LANGUAGE FOR INTELLIGENT AND AUTONOMOUS VEHICLES
- 1 comment
- Log in to post comments
Intelligent transportation is a complex system that involves the interaction of connected technologies, including Smart Sensors, Intelligent and Autonomous Vehicles, High Precision Maps, and 5G. The coordination of all these machines mandates a common language that serves as a protocol for intelligent machines to communicate. International standards serve as the global protocol to satisfy industry needs at the product level. MPEG-CDVA is the official ISO standard for search and retrieval applications by providing Compact Descriptors for Video Analysis (CDVA).
- Categories:
122 Views
High-Throughput JPEG2000 (HTJ2K) is a new addition to the JPEG2000 suite of coding tools; it has been recently approved as Part-15 of the JPEG2000 standard, and the JPH file extension has been designated for it. The HTJ2K employs a new “fast” block coder that can achieve higher encoding and decoding throughput than a conventional JPEG2000 (C-J2K) encoder. The higher throughput is achieved because the HTJ2K codec processes wavelet coefficients in a smaller number of steps than C-J2K.
2498.pdf
- Categories:
225 Views
- Read more about Joint Demosaicking / Rectification of Fisheye Camera Images using Multi-color Graph Laplacian Regularization
- Log in to post comments
- Categories:
10 Views
- Read more about Open-Set Metric Learning for Person Re-identification in The Wild
- Log in to post comments
Person re-identification in the wild needs to simultaneously (frame-wise) detect and re-identify persons and has wide utility in practical scenarios. However, such tasks come with an additional open-set re-ID challenge as all probe persons may not necessarily be present in the (frame-wise) dynamic gallery. Traditional or close-set re-ID systems are not equipped to handle such cases and raise several false alarms as a result. To cope with such challenges open-set metric learning (OSML), based on the concept of Large margin nearest neighbor (LMNN) approach, is proposed.
- Categories:
107 Views
- Read more about Bubblenet: A Disperse Recurrent Structure To Recognize Activities
- Log in to post comments
This paper presents an approach to perform human activity recognition in videos through the employment of a deep recurrent network, taking as inputs appearance and optical flow information. Our method proposes a novel architecture named BubbleNET, which is based on a recurrent layer dispersed into several modules (referred to as bubbles) along with an attention mechanism based on squeeze-and-excitation strategy, responsible to modulate each bubble contribution.
- Categories:
8 Views
- Read more about PerceptNet: A Human Visual System Inspired Neural Network for Estimating Perceptual Distance
- Log in to post comments
Traditionally, the vision community has devised algorithms to estimate the distance between an original image and images that have been subject to perturbations. Inspiration was usually taken from the human visual perceptual system and how the system processes different perturbations in order to replicate to what extent it determines our ability to judge image quality. While recent works have presented deep neural networks trained to predict human perceptual quality, very few borrow any intuitions from the human visual system.
- Categories:
22 Views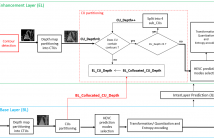
- Read more about DEPTH MAPS FAST SCALABLE COMPRESSION BASED ON CODING UNIT DEPTH
- Log in to post comments
- Categories:
20 Views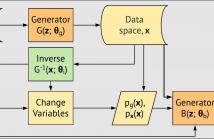
- Read more about Boundary of Distribution Support Generator (BDSG): Sample Generation on the Boundary
- Log in to post comments
- Categories:
114 Views