
ICIP 2020 is a fully virtual conference. The International Conference on Image Processing (ICIP), sponsored by the IEEE Signal Processing Society, is the premier forum for the presentation of technological advances and research results in the fields of theoretical, experimental, and applied image and video processing. ICIP has been held annually since 1994, brings together leading engineers and scientists in image and video processing from around the world. Visit website.

- Read more about Skeleton Action Recognition Based on Singular Value Decomposition
- Log in to post comments
This work introduces new method using the singular value decomposition (SVD) to recognise human activities from skeleton motion sequences. The primary focus was on different activity durations, inaccurate placement of the joints and loss of information about position of the joints. For that we needed to develop a robust model. At first, the pose features are created for description of skeleton pose per frame, that is created by directional vectors to alljoint pairwise combinations without repetition.
- Categories:
 62 Views
62 Views
- Read more about Improving Detection and Recognition of Degraded Faces by Discriminative Feature Restoration Using GAN
- Log in to post comments
Face detection and recognition in the wild is currently one of the most interesting and challenging problems. Many algorithms with high performance have already been proposed and applied in real-world applications. However, the problem of detecting and recognising degraded faces from low-quality images and videos mostly remains unsolved. In this paper, we present an algorithm capable of recovering facial features from low-quality videos and images. The resulting output image boosts the performance of existing face detection and recognition algorithms.
- Categories:
39 Views
- Read more about On Intra Video Coding and In-Loop Filtering for Neural Object Detection Networks
- Log in to post comments
Classical video coding for satisfying humans as the final user is a widely investigated field of studies for visual content, and common video codecs are all optimized for the human visual system (HVS). But are the assumptions and optimizations also valid when the compressed video stream is analyzed by a machine? To answer this question, we compared the performance of two state-of-the-art neural detection networks when being fed with deteriorated input images coded with HEVC and VVC in an autonomous driving scenario using intra coding.
- Categories:
44 Views
In this paper, a new robust principal component analysis (RPCA) method is proposed which enables us to exploit the main components of a given corrupted data with non-Gaussian outliers. The proposed method is based on the alpha-divergence which is a parametric measure from information geometry. The proposed method which is adjustable by the hyperparameter alpha, reduces to the classical PCA under certain parameters.
- Categories:
131 Views
- Read more about Fundamental Limits Of Steganographic Capacity For Multivariate-Quantized-Gaussian-Distributed Multimedia
- Log in to post comments
Steganography is the art and science of hiding data within innocent-looking objects (cover objects). Multimedia objects such as images and videos are an attractive type of cover objects due to their high embedding rates. There exist many techniques for performing steganography in both the literature and the practical world. Meanwhile, the definition of the steganographic capacity for multimedia and how to be calculated has not taken full attention.
- Categories:
38 Views
- Read more about The Good, the Bad, and the Ugly: Neural Networks Straight from JPEG
- Log in to post comments
Over the past decade, convolutional neural networks (CNNs) have achieved state-of-the-art performance in many computer vision tasks. They can learn robust representations of image data by processing RGB pixels. Since image data are often stored in a compressed format, from which JPEG is the most widespread, a preliminary decoding process is demanded. Recently, the design of CNNs for processing JPEG compressed data has gained attention from the research community.
- Categories:
61 Views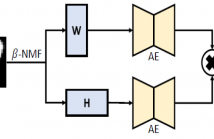
- Read more about Unsupervised learning from limited available data by β-NMF and dual autoencoder
- Log in to post comments
Unsupervised Learning (UL) models are a class of Machine Learning (ML) which concerns with reducing dimensionality, data factorization, disentangling and learning the representations among the data. The UL models gain their popularity due to their abilities to learn without any predefined label, and they are able to reduce the noise and redundancy among the data samples.
- Categories:
62 Views
- Read more about DETECTION OF SHIP WAKES IN SAR IMAGERY USING CAUCHY REGULARISATION
- Log in to post comments
- Categories:
28 Views
- Read more about FDFlowNet: Fast Optical Flow Estimation using a Deep Lightweight Network
- 2 comments
- Log in to post comments
FDFlowNet.pdf
- Categories:
203 Views
- Read more about CHANNEL SHUFFLE RECONSTRUCTION NETWORK FOR IMAGE COMPRESSIVE SENSING
- Log in to post comments
- Categories:
42 Views