
- Read more about Analysis Dictionary Learning: An Efficient and Discriminative Solution
- Log in to post comments
- Categories:
 10 Views
10 Views
- Read more about MATERIAL IDENTIFICATION USING RF SENSORS AND CONVOLUTIONAL NEURAL NETWORKS
- Log in to post comments
Recent years have assisted a widespreading of Radio-Frequency-based tracking and mapping algorithms for a wide range of applications, ranging from environment surveillance to human-computer interface.
poster.pdf
- Categories:
27 Views
We present a novel event embedding algorithm for crime data that can jointly capture time, location, and the complex free-text component of each event. The embedding is achieved by regularized Restricted Boltzmann Machines (RBMs), and we introduce a new way to regularize by imposing a ℓ1 penalty on the conditional distributions of the observed variables of RBMs. This choice of regularization performs feature selection and it also leads to efficient computation since the gradient can be computed in a closed form.
- Categories:
91 Views
- Read more about Reconstruction-free deep convolutional neural networks for partially observed images
- Log in to post comments
Conventional image discrimination tasks are performed on fully observed images. In challenging real imaging scenarios, where sensing systems are energy demanding or need to operate with limited bandwidth and exposure-time budgets, or defective pixels, where the data collected often suffers from missing information, and this makes the task extremely hard. In this paper, we leverage Convolutional Neural Networks (CNNs) to extract information from partially observed images.
- Categories:
39 Views
- Read more about A MACHINE LEARNING APPROACH FOR THE CLASSIFICATION OF INDOOR ENVIRONMENTS USING RF SIGNATURES
- Log in to post comments
Efficient deployment of Internet of Things (IoT) sensors primarily depends on allowing the adjustment of sensor power consumption according to the radio frequency (RF) propagation channel which is dictated by the type of the surrounding indoor environment. This paper develops a machine learning approach for indoor environment classification by exploiting support vector machine (SVM) based on RF signatures computed from real-time measurements.
- Categories:
11 Views
- Read more about Feature Dimensionality Reduction with Graph Embedding and Generalized Hamming Distance
- Log in to post comments
Principal component analysis (PCA) and linear discriminant analysis (LDA) are the most well-known methods to reduce the dimensionality of feature vectors. However, both methods face challenges when used on multilabel data—each data point may be associated to multiple labels. PCA does not take advantage of label information thus the performance is sacrificed. LDA can exploit class information for multiclass data, but cannot be directly applied to multilabel problems. In this paper, we propose a novel dimensionality reduction method for multilabel data.
- Categories:
59 Views
This paper presents three fully convolutional neural network architectures which perform change detection using a pair of coregistered images. Most notably, we propose two Siamese extensions of fully convolutional networks which use heuristics about the current problem to achieve the best results in our tests on two open change detection datasets, using both RGB and multispectral images. We show that our system is able to learn from scratch using annotated change detection images.
- Categories:
76 Views
- Read more about CYCLIC ANNEALING TRAINING CONVOLUTIONAL NEURAL NETWORKS FOR IMAGE CLASSIFICATION WITH NOISY LABELS
- Log in to post comments
Noisy labels modeling makes a convolutional neural network (CNN) more robust for the image classification problem. However, current noisy labels modeling methods usually require an expectation-maximization (EM) based procedure to optimize the parameters, which is computationally expensive. In this paper, we utilize a fast annealing training method to speed up the CNN training in every M-step.
- Categories:
36 Views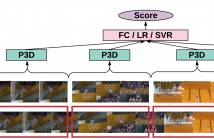
- Read more about S3D: Stacking Segmental P3D for Action Quality Assessment
- 1 comment
- Log in to post comments
Action quality assessment is crucial in areas of sports, surgery and assembly line where action skills can be evaluated. In this paper, we propose the Segment-based P3D-fused network S3D built-upon ED-TCN and push the performance on the UNLV-Dive dataset by a significant margin. We verify that segment-aware training performs better than full-video training which turns out to focus on the water spray. We show that temporal segmentation can be embedded with few efforts.
- Categories:
107 Views
- Read more about MINTIN: MAXOUT-BASED AND INPUT-NORMALIZED TRANSFORMATION INVARIANT NEURAL NETWORK
- Log in to post comments
- Categories:
12 Views